Machine Learning / NLP / AI
#currentwork
#oldglories
John started working professionally with Neural Networks in 2002, in the Linguistics Center of the University of Lisbon.
During the next 4 years, he conceived, created, trained and deployed a full infrastructure toolchain for morpho-syntactic analisys of corpora for Part-of-Speech (PoS) tagging. These results were shared and validated by teams of PhDs, top researchers in the fields of Computational Linguistics, Morphology, Syntax, Phonetics, and Language NeuroBiology. The people he worked with used the tooling he created to produce and publish academic papers, while also providing valuable feedback and suggestions for improvement at its various stages and iterations.
The PoS Tagger was a piece of software that took a transcribed corpus (oral, newspaper, etc) on one end, and produced an annotated text, adding a Part-of-Speech (PoS) tag to every word denoting its morpho-syntactic category. At certain points, the hit rate was close to 98.5%.
The "magic" of "guessing" the correct Part-of-Speech (PoS) was achieved by creating a Neural Network and statistically training it on specialized corpora that had been collected throughout the years, achieving a finely crafted manually annotated corpus, full with examples from which the Neural Network could train its statistical inference (i.e., "learn"). This provided several examples of the possibility of a word being assigned a numeric probability of being of a certain category, depending on its placement with relation to other words within the sentence.
From the operational standpoint, and by leveraging the available engineering and design capabilities, this was achieved by creating a master process task pipeline composed of:
- pre-processing the text through scripts to make it suitable for evaluation;
- evaluating each word token through a Neural Network;
- reconstructing the text from the Neural Network's output - now with an associated Part-of-Speech (PoS);
- post-processing the text through scripts, to make adjustments, adhere to pre-defined norms and standards, and most importantly, identify and mark idiomatic expressions, annotate locutions, and place speech styling markers;
The Neural Network itself needed to undergo training before being ready to be used. It started off as a core created in C Language, with empty weights. As the training progressed, weights representing the probability for each word and category pairing were adjusted, as they came along. The C file, with this huge matrix of the probabilistic weights being proposed, was then compiled, producing a binary that took a piece of text and, wheighing the probabilities on its matrix, produced a Part-of-Speech (PoS) tag for each word as output. This compiled core was invoked and executed by the set of scripts (on the text to now be tagged).
The underlying idea was that a word can be tagged with a different Part-of-Speech (PoS) tag depending on its placement within a certain word context. The same word can be a Noun or a Verb (e.g: Fly), but the surrounding words taken on with their categories can give a pondered matrix to look up the most probable Part-of-Speech (PoS) tags for this word in this particular placement. Unlike traditional programming, where we're limited to if-then-else or case-based Imperative constructs, this allows us to have a Bayesian approach to problem solving in Part-of-Speech (PoS) tagging.
Below you can see original pictures of three different phases of the training process (yes, that's Windows XP). The error rate starts going down as the Neural Network starts adjusting its weights, trying to match what's actually being found in the training corpus.
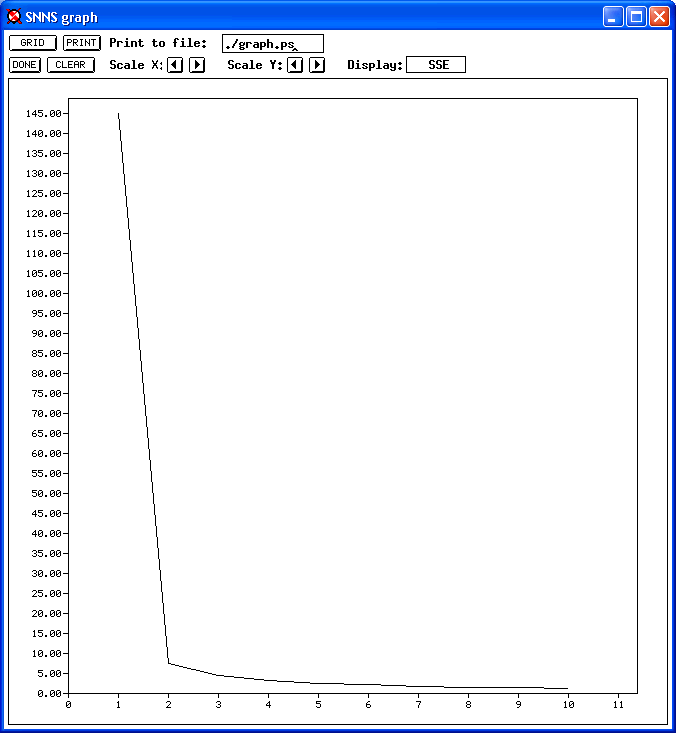
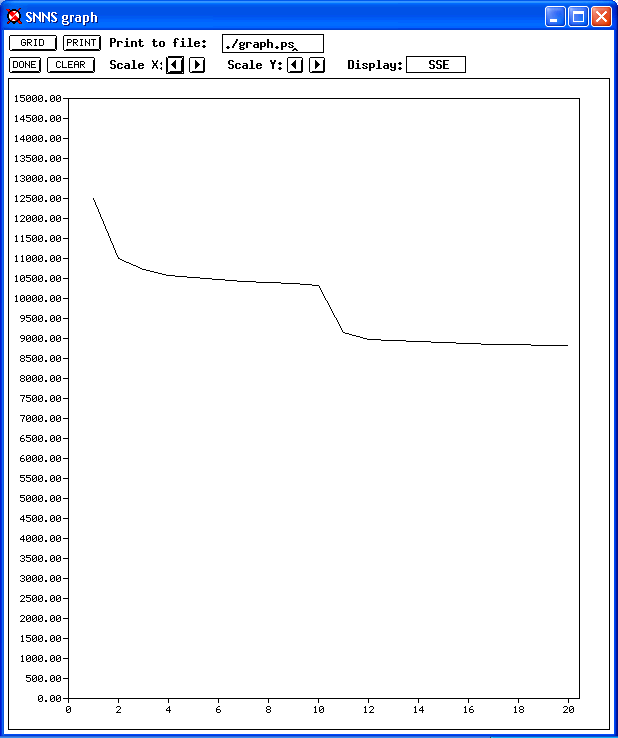
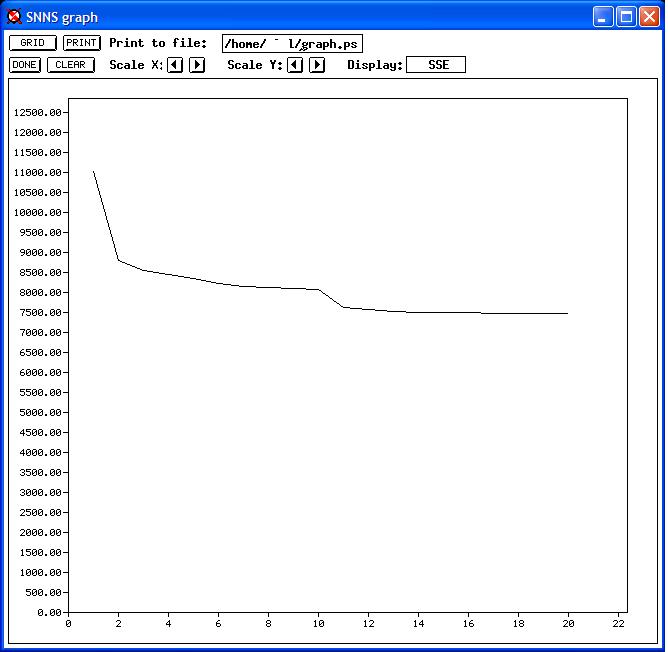
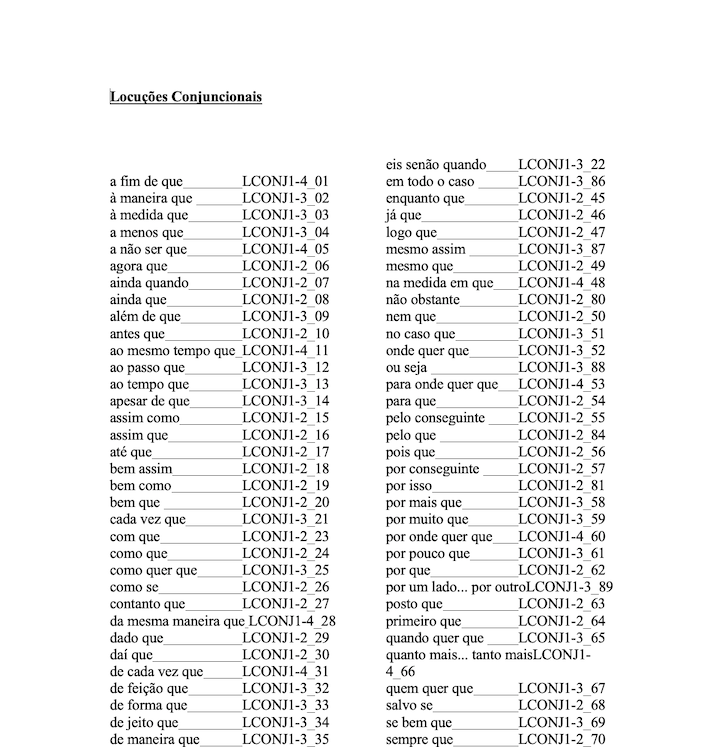
The post-processing was non-trivial. A big part of the effort being put into the Corpus was in institutionally identifying and defining an extensive list of locutions, or locution phrases, and with the experience gained, to annotate the Corpus with them.
Locutions are words or phrases used idiomatically, both in style and as a speech marker. They may roughly correspond to "Catchphrases" or "Idioms" (also called "Idiomatic Expressions"), though some are more complex or are mixed with different Parts-of-Speech (PoS).
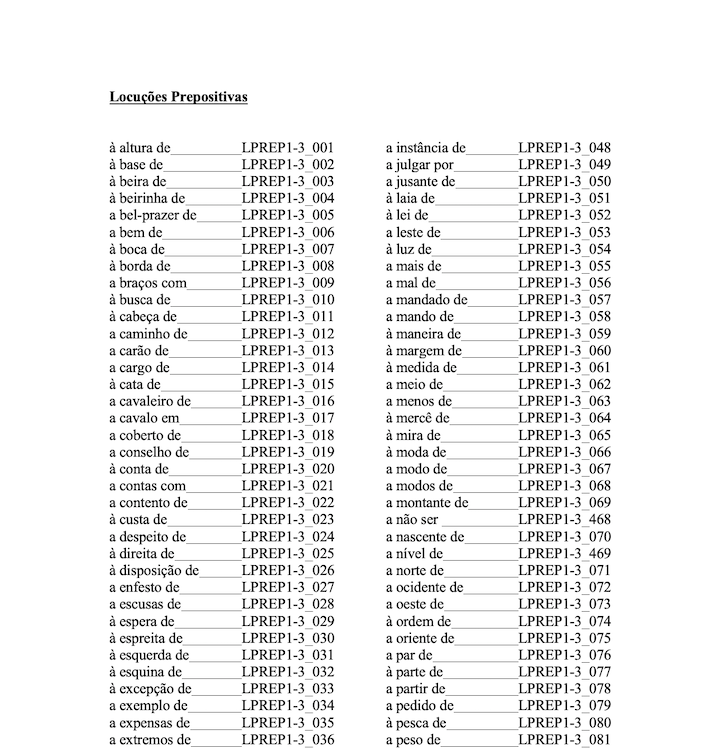
Some of the annotation of the Locutions conflicted with the tagging from the Neural Network, and figuring out how to correctly tag the Corpus was the challenge behind the Post-Processing. Some Locutions are based on Adverbs, some on Prepositions, some Verbal, there's a wide variety.
Here are some examples of Locutions that were featured in the Corpus, some are easy, others not all that much:

The software being used was the Stuttgart Neural Network Simulator, a package that included command line tools and a GUI interface native to X-Window. It featured a graphical interface and allowed the training to be monitored and graphed, which was a good support.
Stuttgart Neural Network Simulator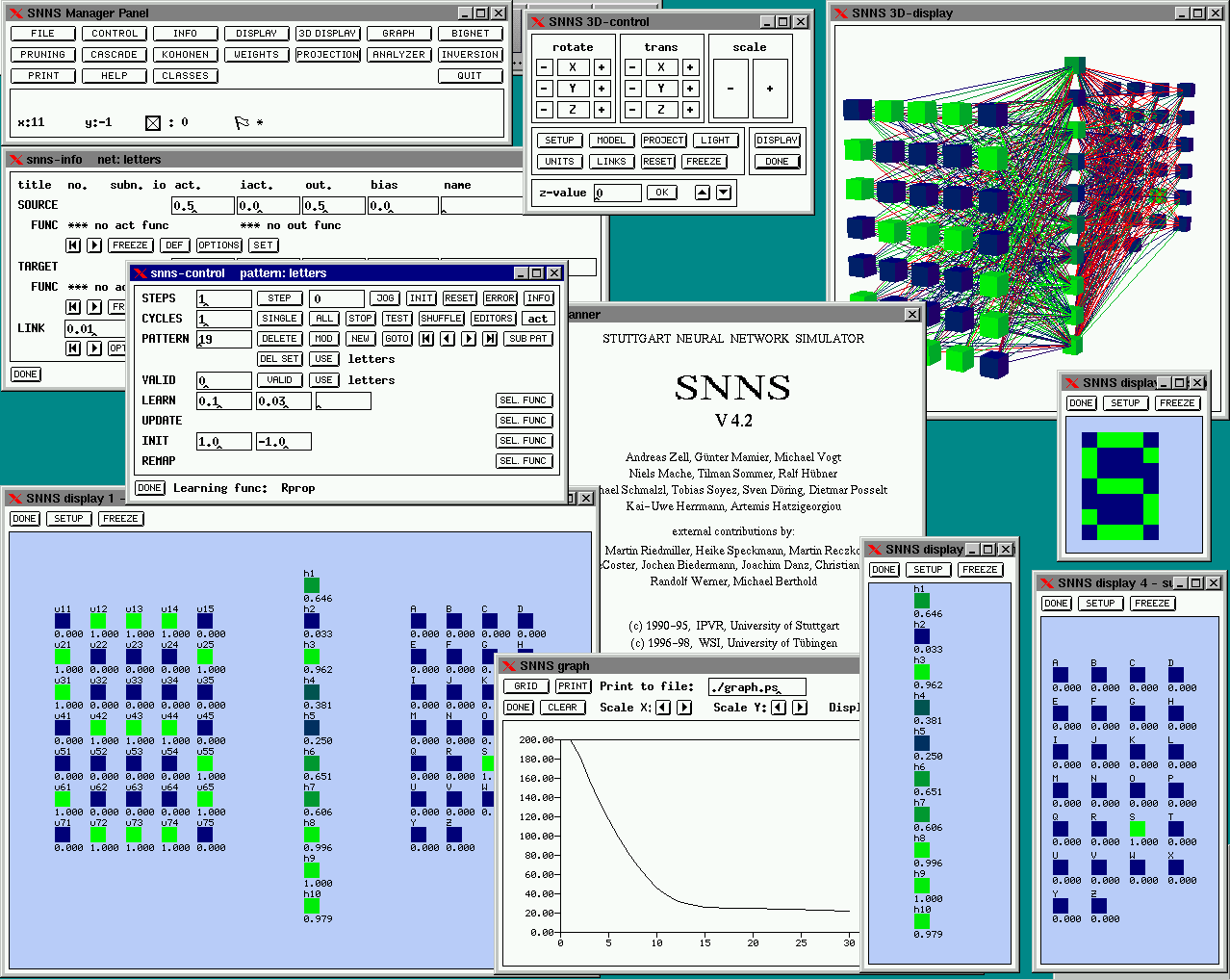
Training and serving the results was done using a SPARCserver, running Solaris 2.5.1.
SNNS rocks.
C rocks.
Morpho-syntactic Part-of-Speech (PoS) taggers rock.
So it was pretty awesome.
Current Stack
With my background in DevOps, Cloud Engineering, and Virtualization, I'm always looking for ways to optimize deployments and systems. With this generation of AI tools, these are the points I keep an eye on:
- Optimize the capacity to evaluate a model's performance, fine-tuning, and accuracy
- My continued ability to ship LLM / RAG systems end-to-end
- What's the familiarity of the tools with vector search, embeddings, and retrieval design
I'll write a more detailed article on MLOps, with the philosophy and practice of reconciling the evolution, but currently some tools deserve a mention for finding their way into my toolkit.
- Whisper Batched Audio Transcription
With Speaker ID - 8 GPU 40 CPU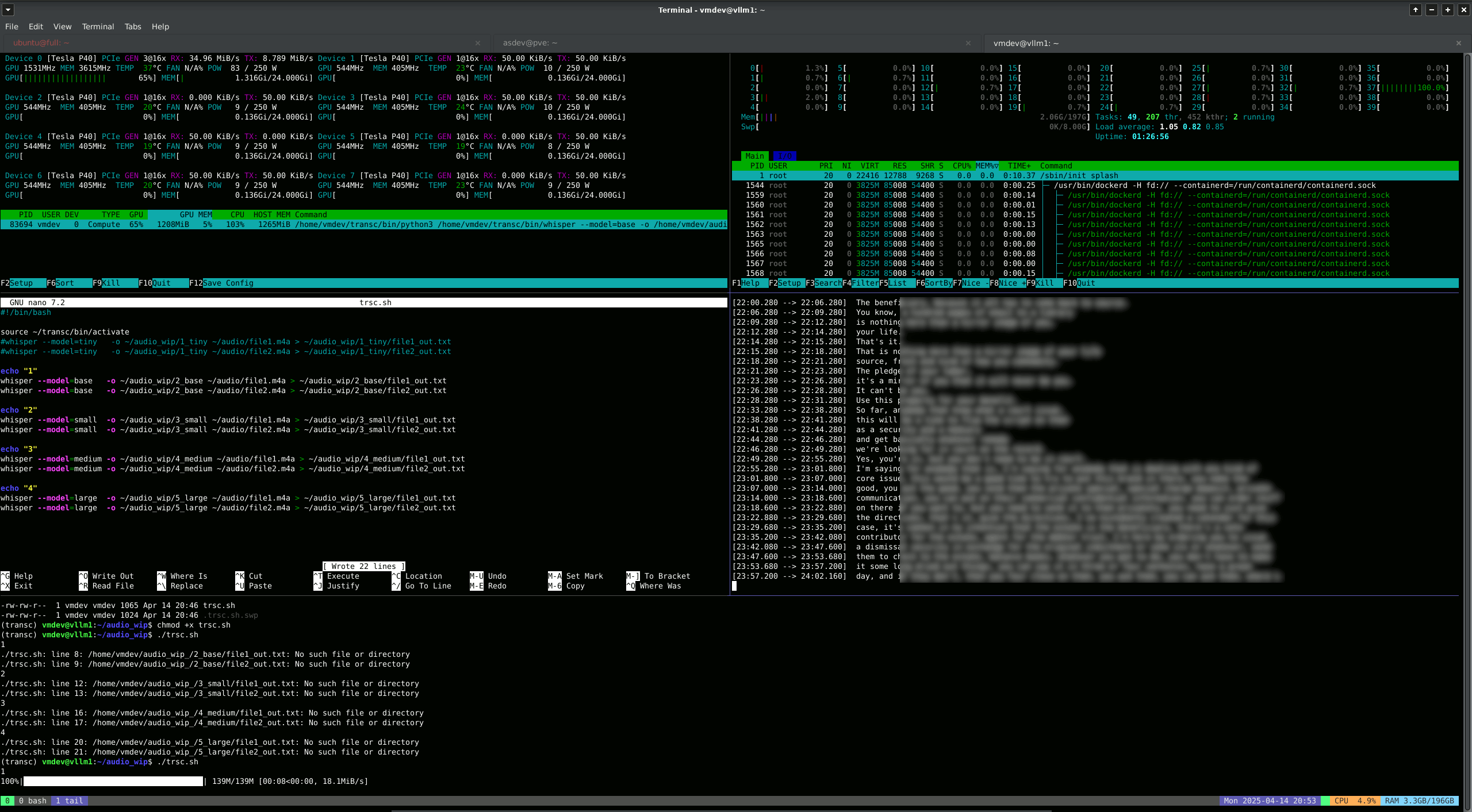
- Whisper Audio Transcription Script
Nvidia CUDA and Pytorch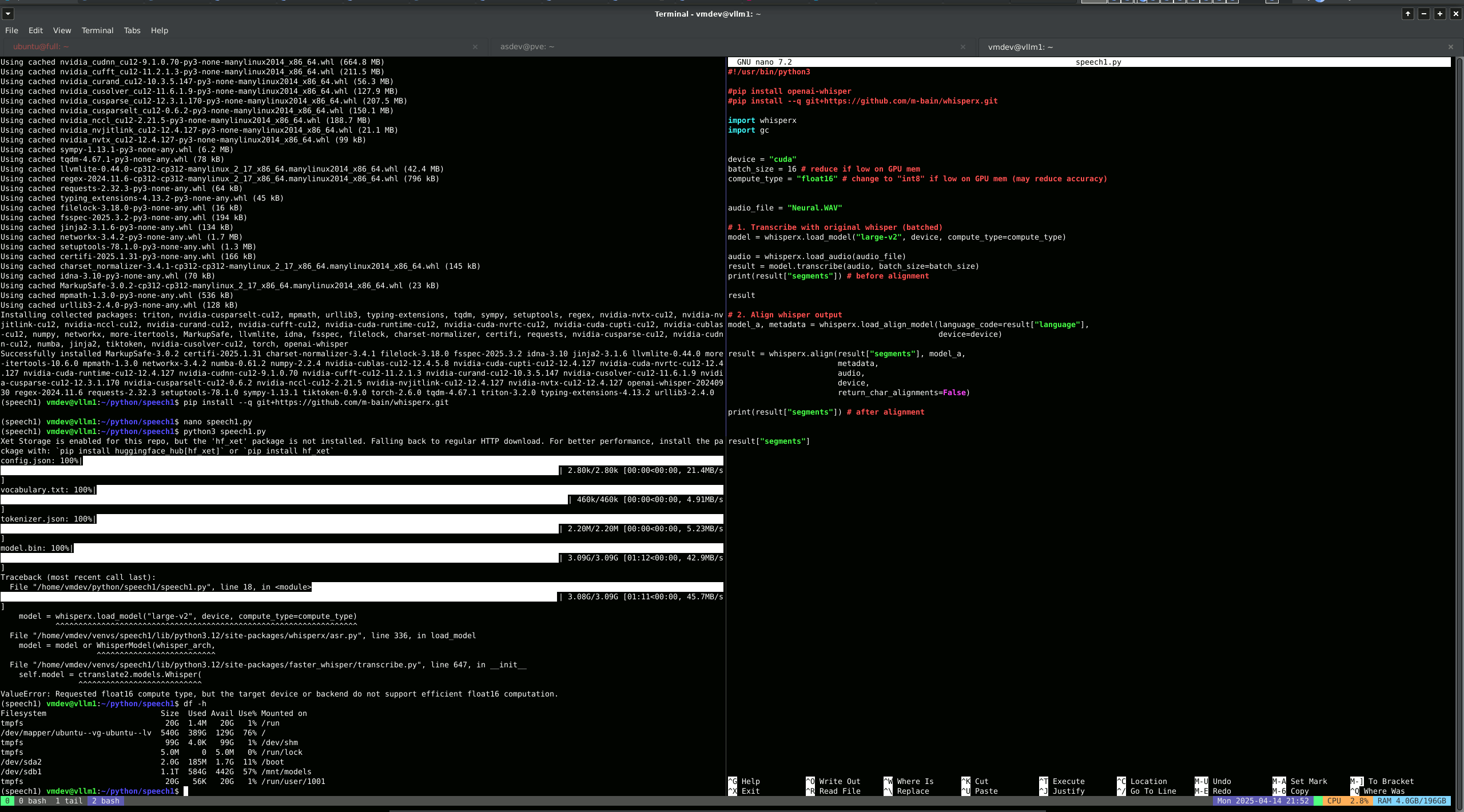
- vLLM Server OpenAI API Call
CURL Command Line - 8 GPU 40 CPU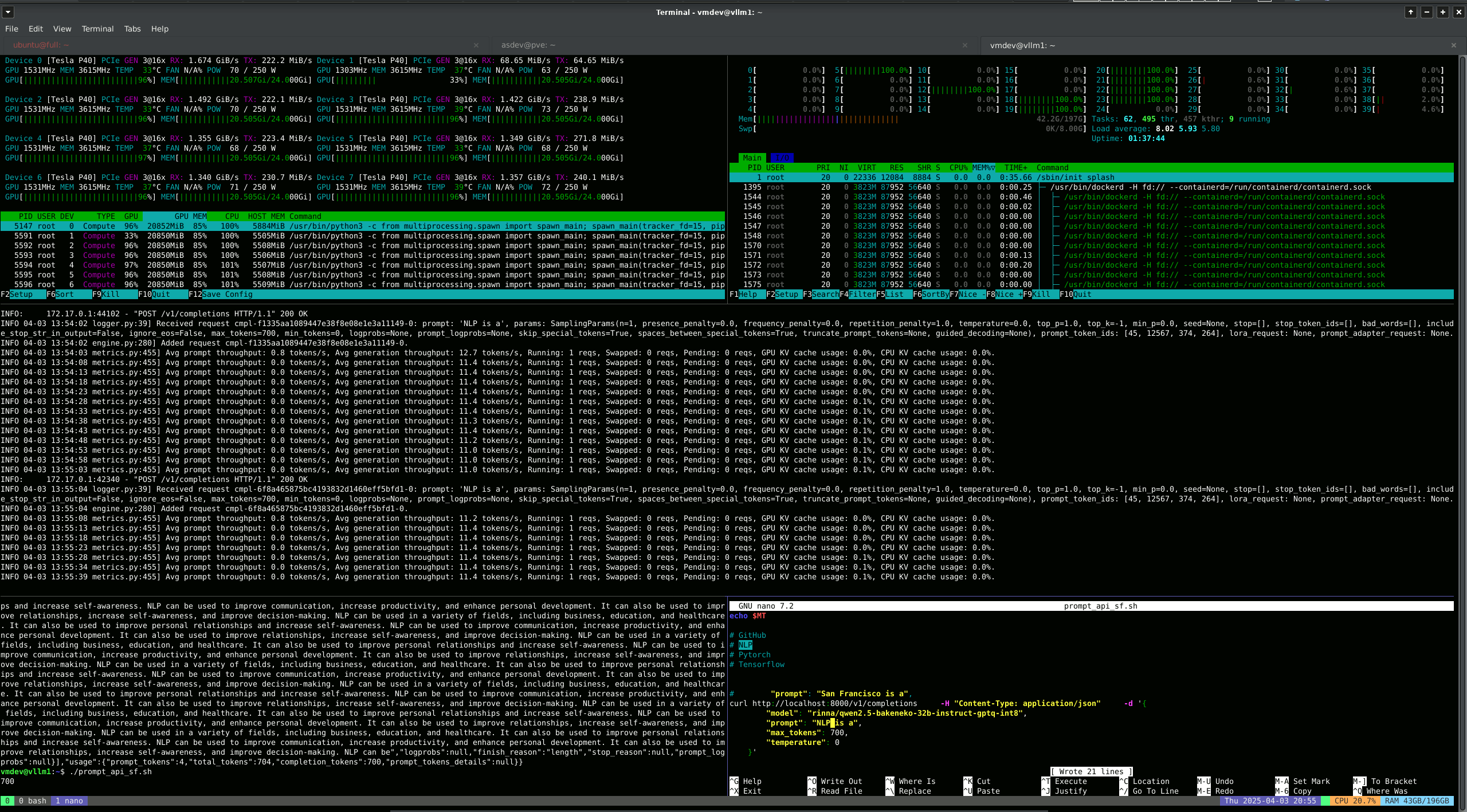
In 2025 (Annum AGI), these are the pieces that are proving to work for me (screenhots of practical client examples below, followed by tool stack):
- vLLM (Model Serving)
- Ray (Multi-Node Clustering in Python)
- MLFlow (ML Ops)
- Proxmox (Virtualization Stack)
- Docker (Containerization)
- K3S / K3D (Orchestration)
- NVIDIA CUDA
- NVIDIA Nsight Systems (Nsight Compute)
- NVIDIA Triton Inference Server
- Keras
- TensorFlow
- Ollama
- DeepSeek
- Kimi-K2
- Python
- LangChain (Agent Framework)
- Bash
- tmux
- FastAPI (Web Operations and DB access)
- OpenRouter
- MarkerPDF (OCR Stack)
- WhisperX (Transcription / Speaker Diarization Stack)
- LanceDB (Vector Database and RAG)
- ComfyUI (Node-Based Frontend - Image Generation)
- SD3.5 (Stable Diffusion - Image Generation)
- AnythingLLM (MCP - Model Context Protocol and Agentic Framework) Server Installation
- OpenWebUI (MCP - Model Context Protocol and Web Frontend)
- PostgreSQL and VectorDB Extension (Vector Database and RAG)
- Runpod (GPU Infrastructure Provider and API)
- Vast.AI (GPU Infrastructure Provider and API)
I don't share much of my client work in my portfolio. You can pick up on some of what I do in here:
(follow the AI link)
Inquire