Some work
This is a page where we show some of our work. Most of it is not public, for virtue of being costumer code, so we've selected a few to give you an insight on what goes into the engineering worx we do around here.
We don't really trust public repos to hold costumer code, we tend to use private repositories instead. We use Git as version control and BitBucket as our primary Git hosting choice.
You can request BitBucket Repository Access, if you're eligible. To do so, please send us an email and enter your BitBucket account email address after clicking the buttton below. Also mention the repo you'd like to have access to. You will be invited based on eligibility.
Go to BitBucket (private) Request BitBucket Repository Access
You can download a .zip file, containing all the following images on this work page for offline viewing.
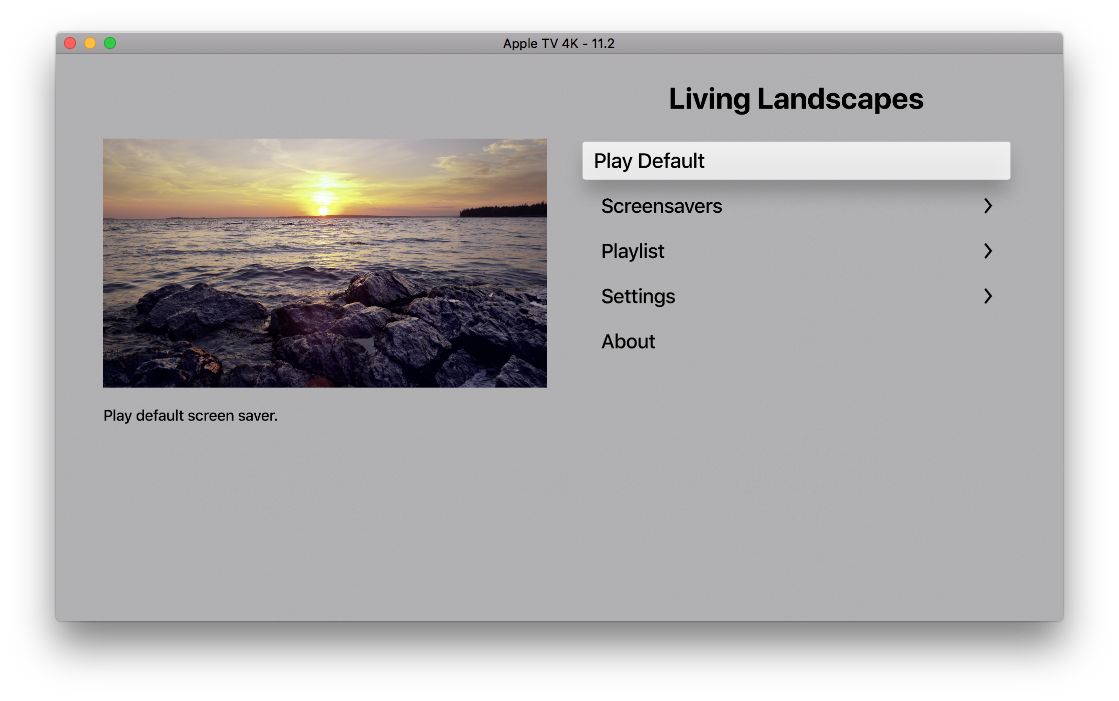
App Development
Android / Kotlin
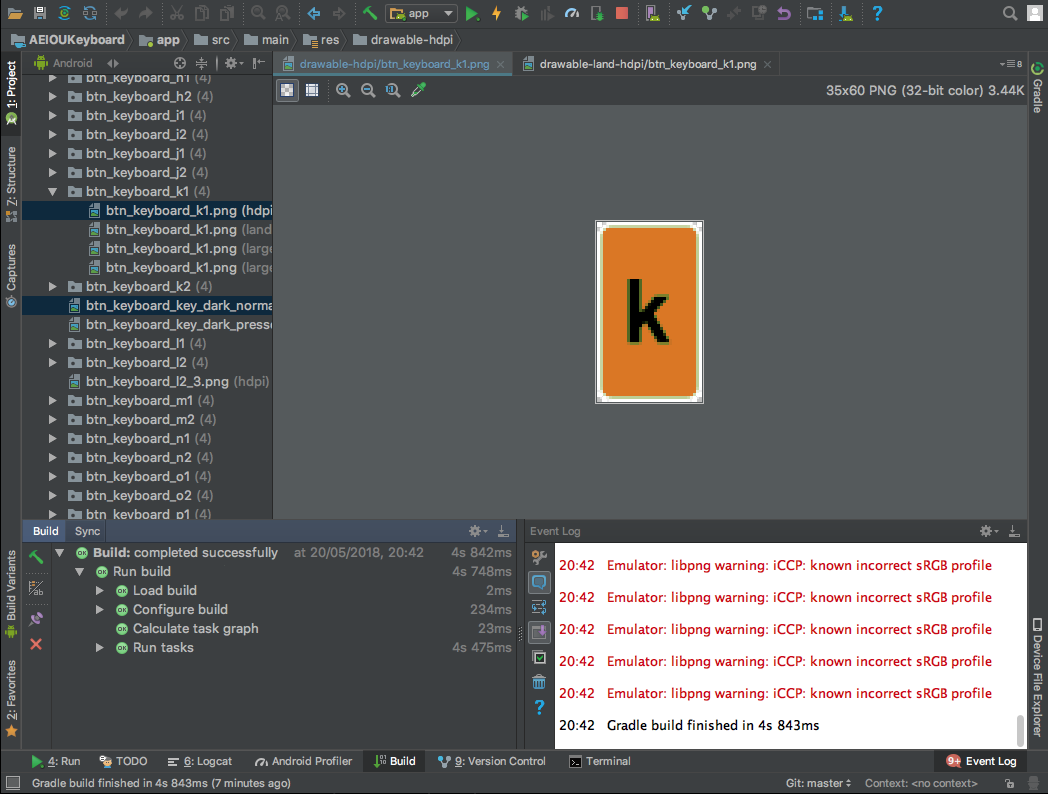
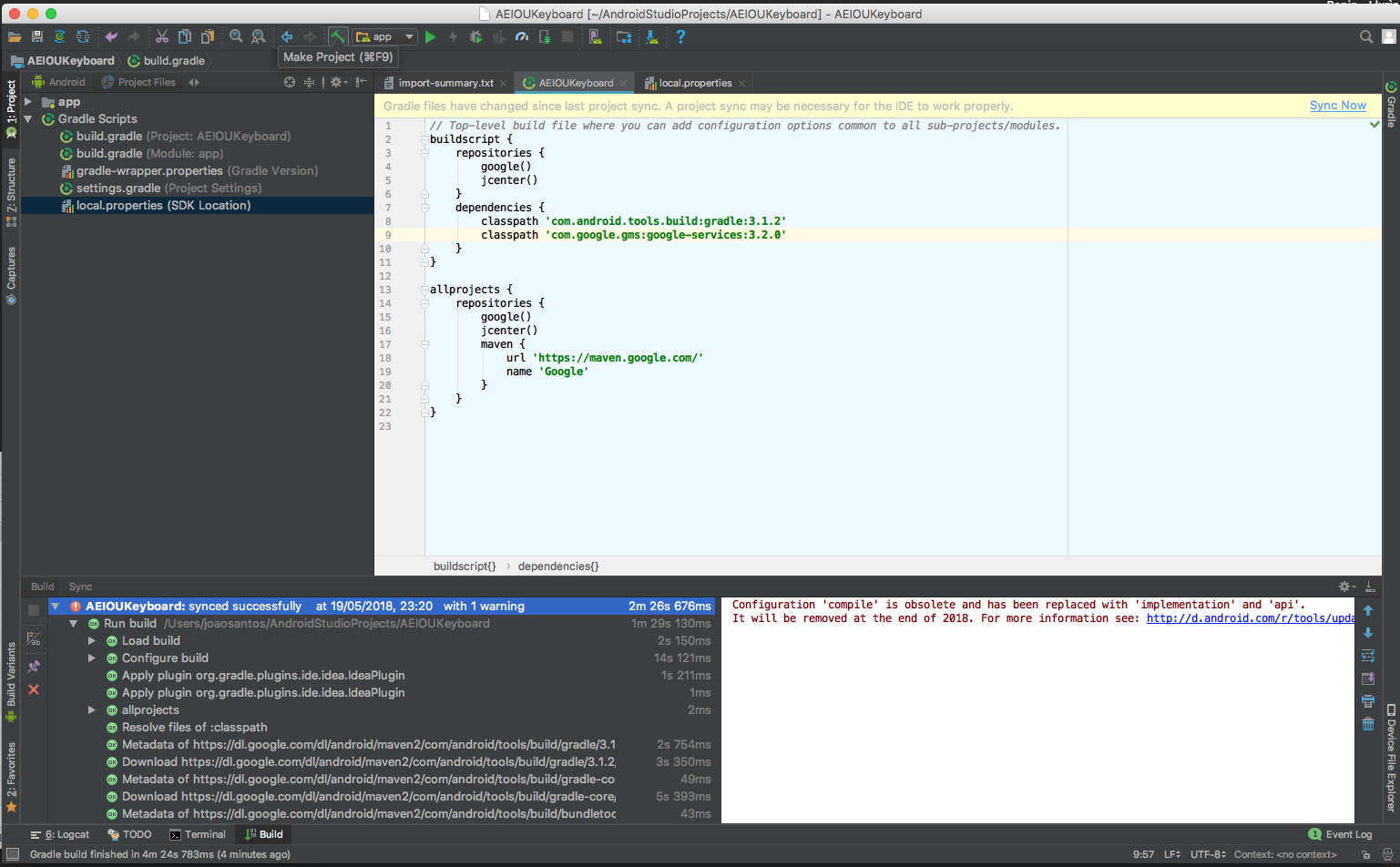
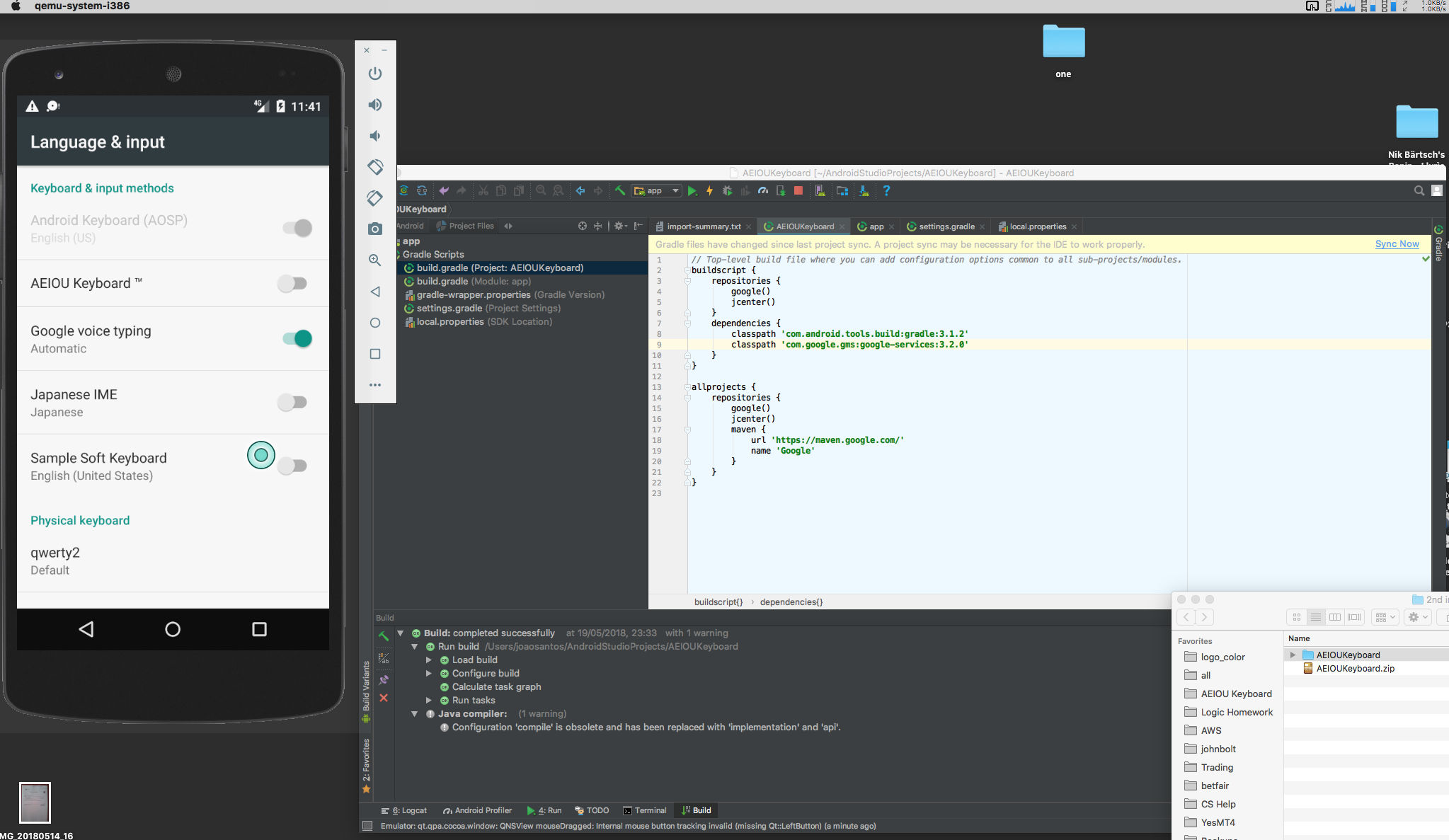
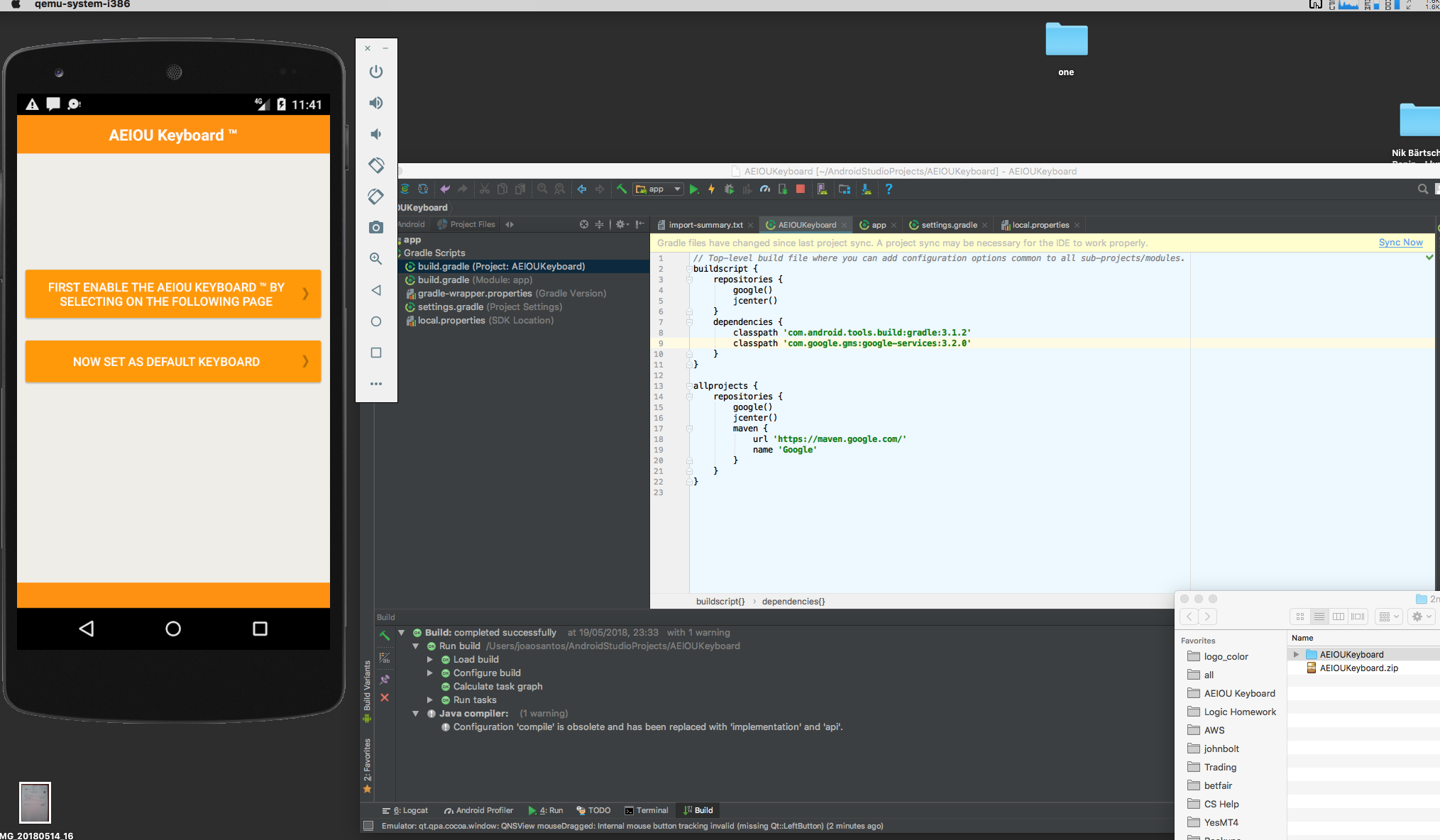
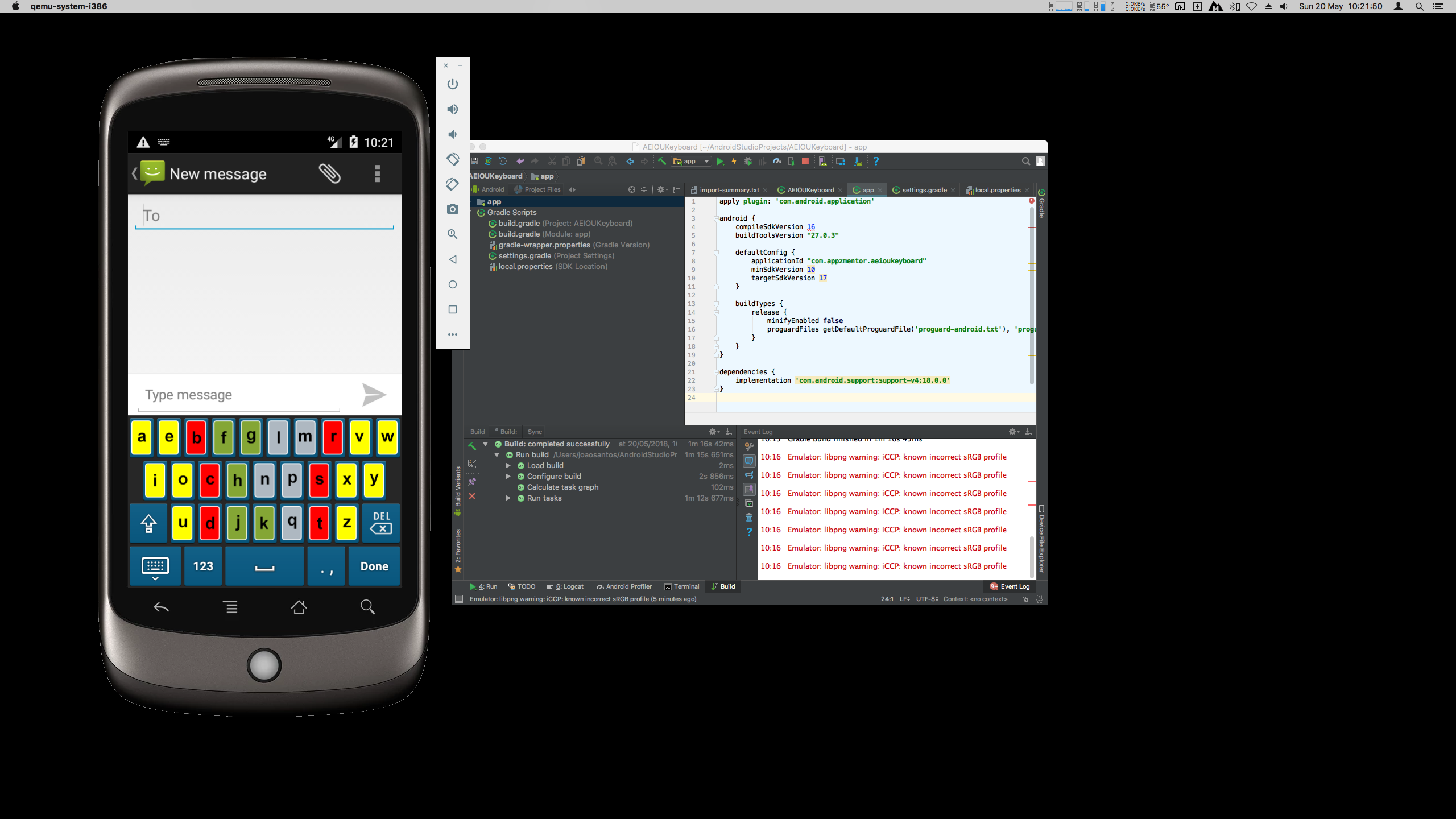
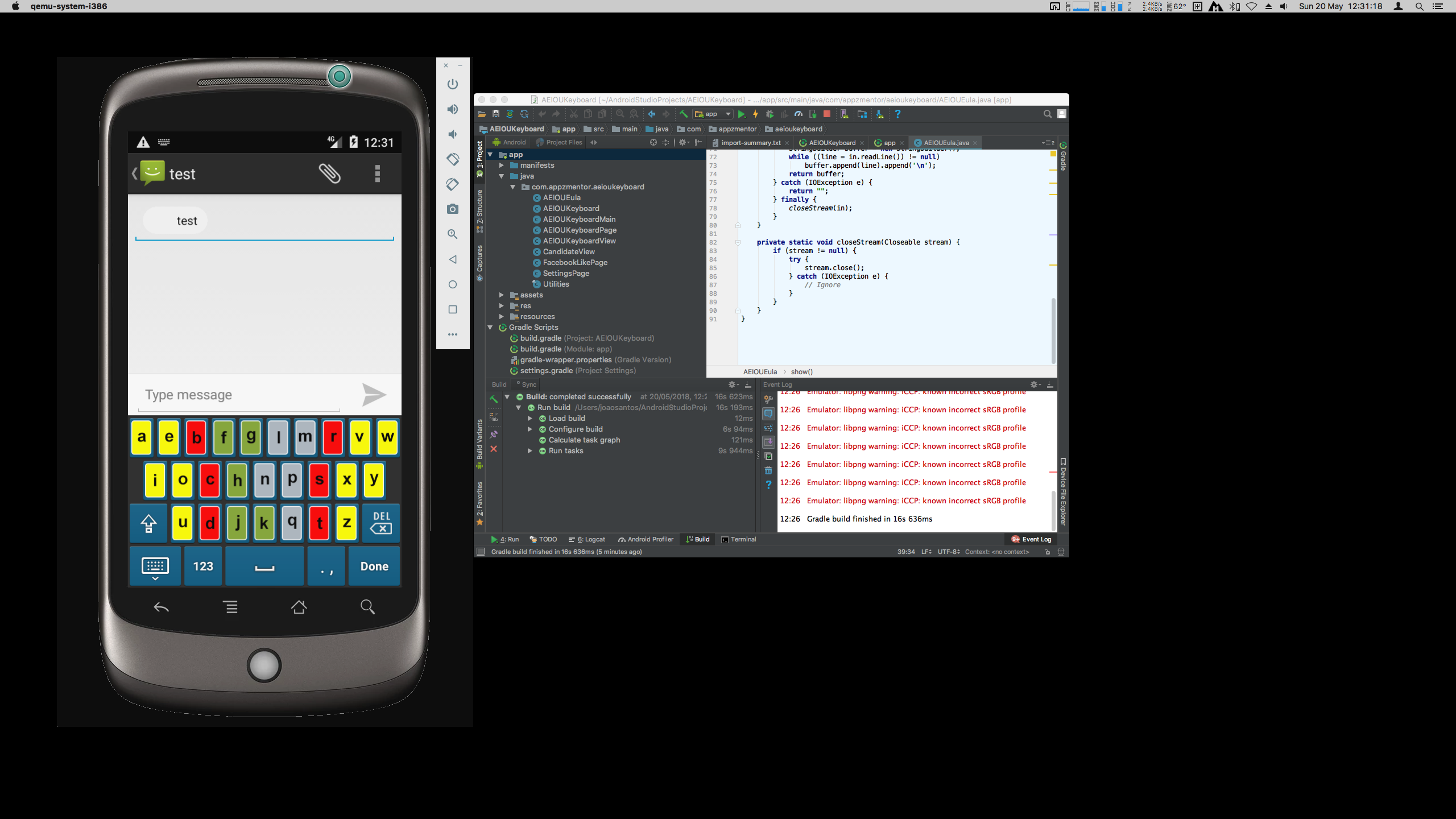
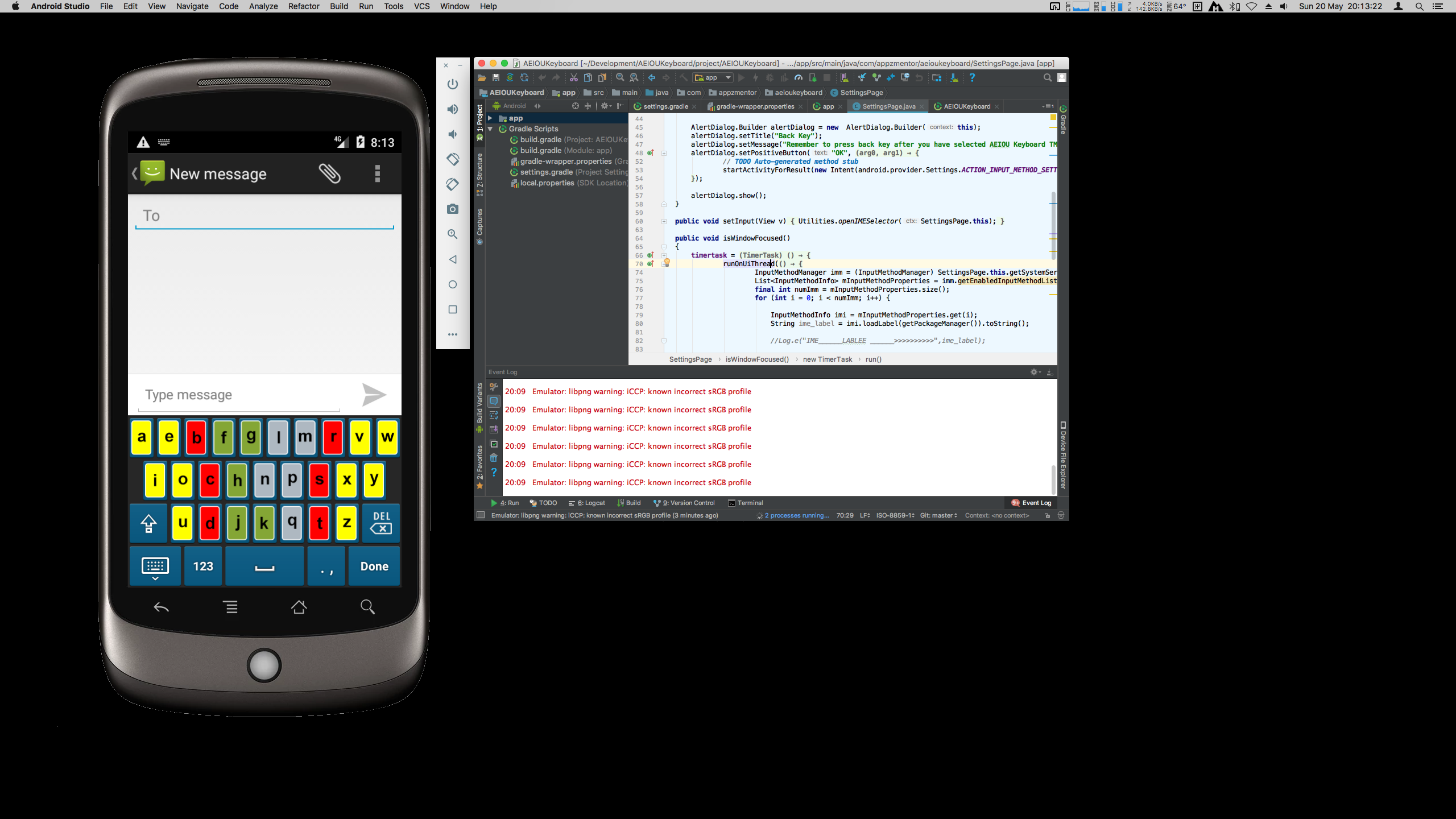
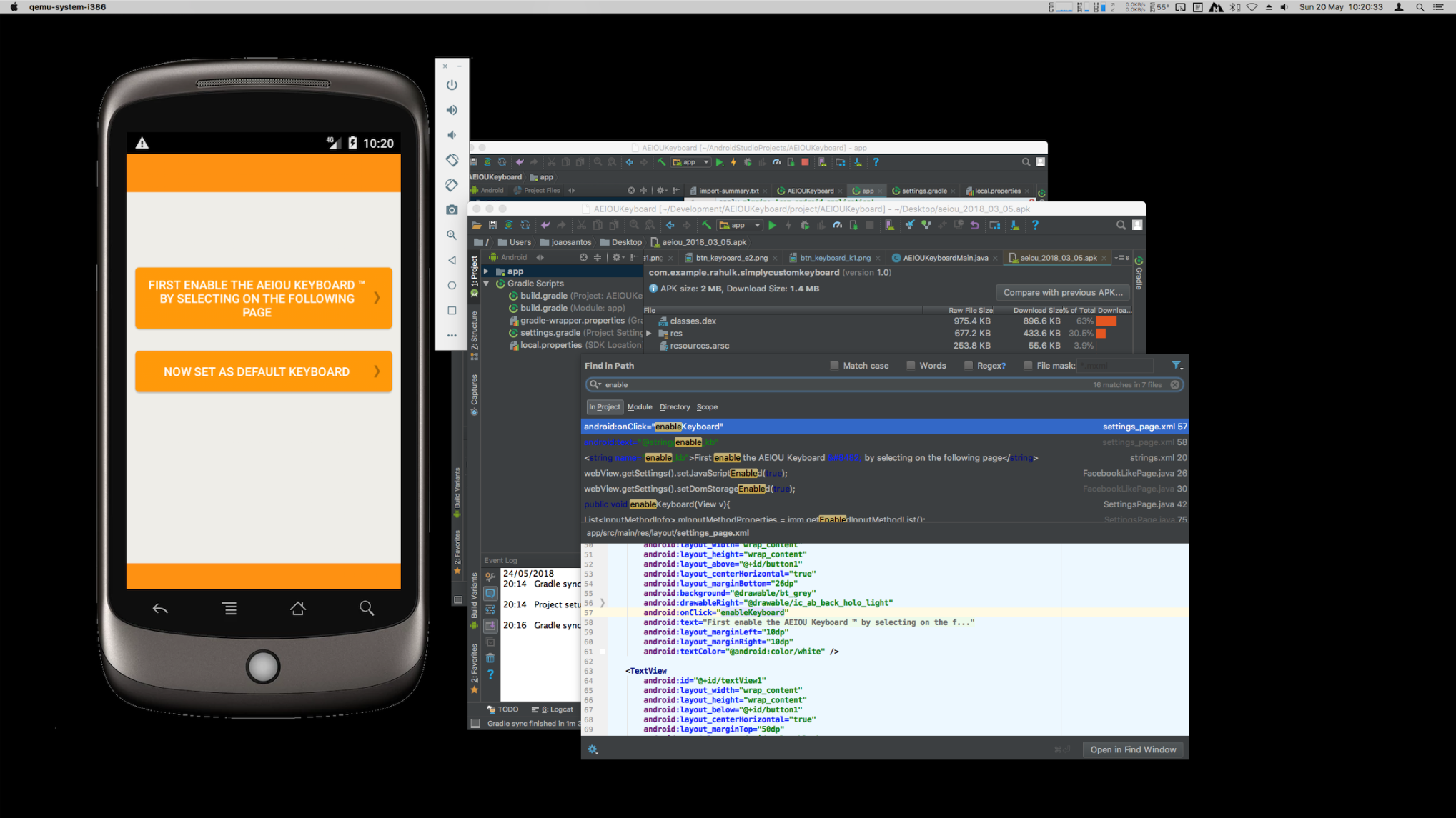
Here you can see some examples of an Android application's inner workings, a multi-colored alternative keyboard for beginning typists. Shown is the debugging of errors while implementing a deplyoment process using Gradle, with the goal of creating a valid build system that will allow us to have a deployed APK package on the target, which can be a phone / tablet, or a simulator. While what is shown is the Android application (mainly, on Android Studio), we were later commissioned to also execute the iOS version of the same app.
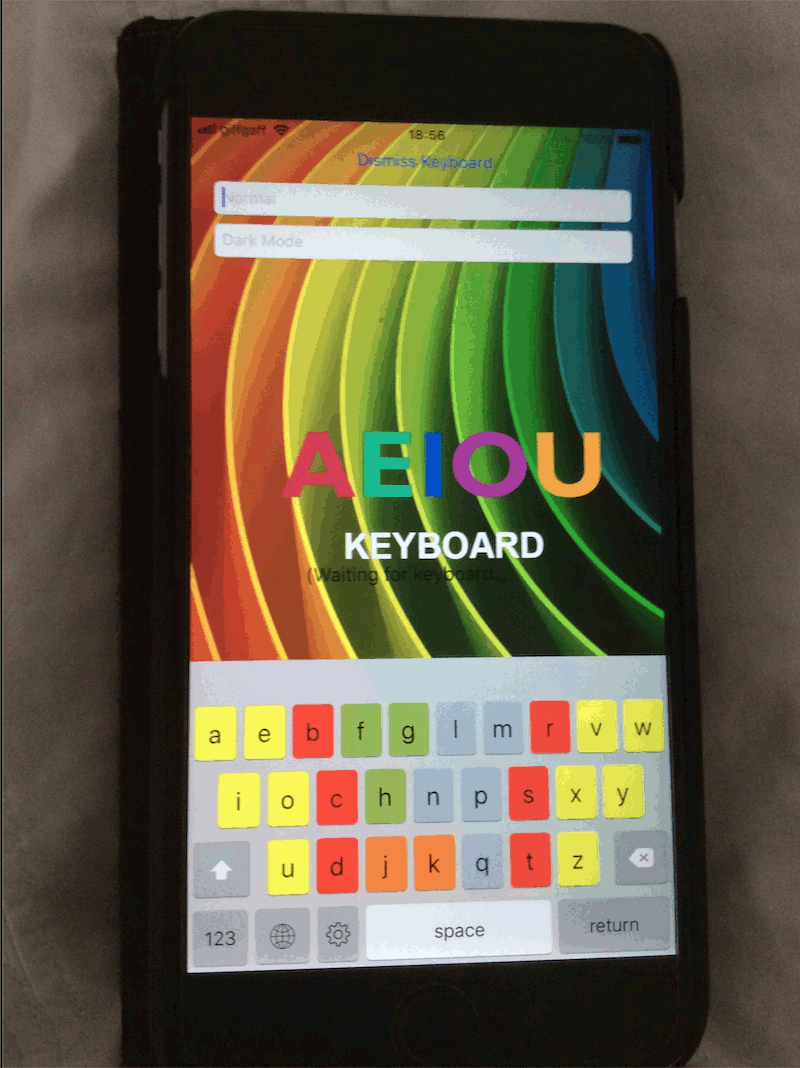
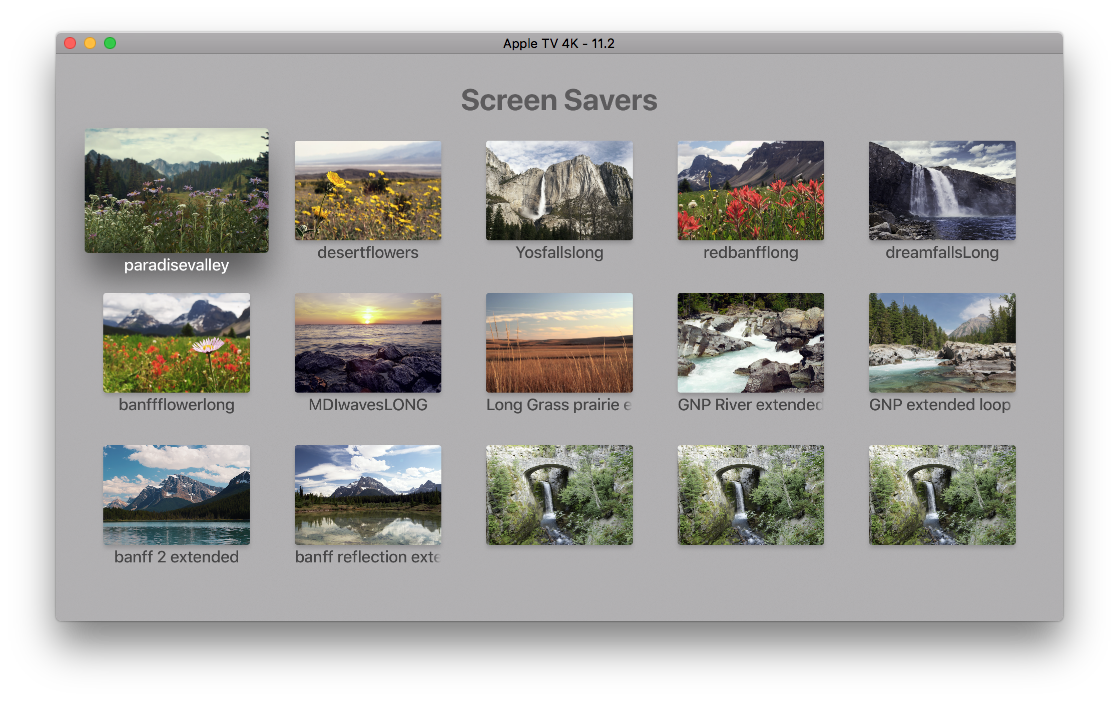
iOS / TVOS
This is the early stage of development of an iOS / TVOS application for displaying Hight Definition landscape screensaver videos and playlists.
The video starts by showing the build process being completed. It does take a while, code builds are very boring.
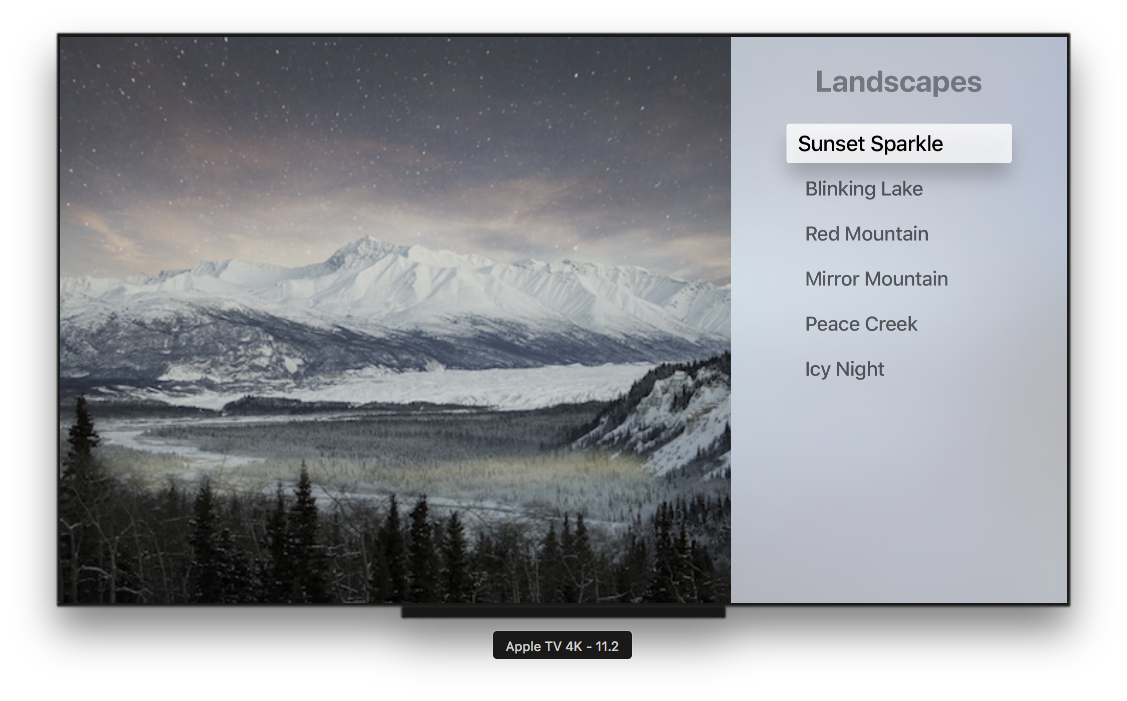
Then, the application window shows up, displaying an early prototype for the proof of concept.
We simulate the moves we'd do using a TV remote.
We can interact with it. When we do, messages are being exchanged between the client and server parts of our application.
They're network communications, and we can see them taking place in the command line text window, at the bottom.
We're verifying our actions against the logs, loading resources, validating that the client-server architecture is fully implemented and working.
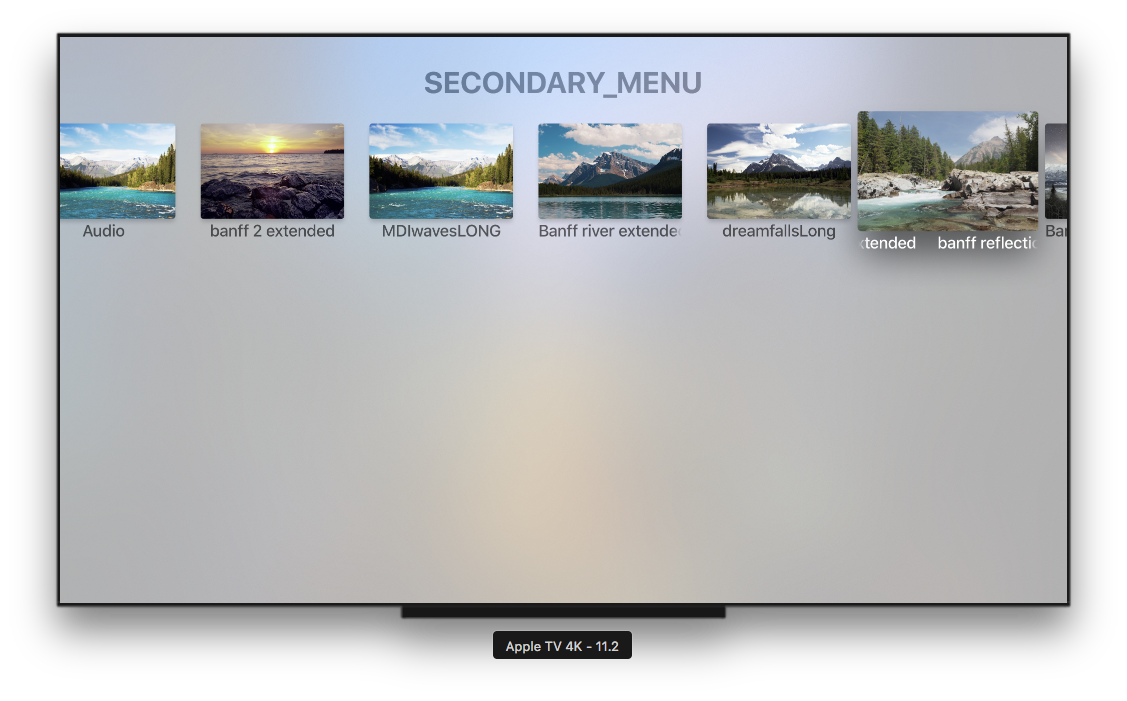
As requests are exchanged between the client and the server, a tour starts to take place, in order to familiarize the client with the capabilities of the platform and possible future directions.
This varies from project to project, but as the scope gets more defined and expectations start being met, these demonstrations tend to become more and more specific down the line, as one would expect.
We use Agile in an iterative process. So this would be an early validation / discovery type of engagement, in order to confirm expectations and assess possibilities for future directions.
Here are some more screenshots of the development process.
Blockchain
Crypto Trading Automation Infrastructure
Live link in Labs.
BlockChain Analytics - On and Off-Chain
Live link in Labs.
Bitcoin-based Private Blockchain Implementation - Case Study
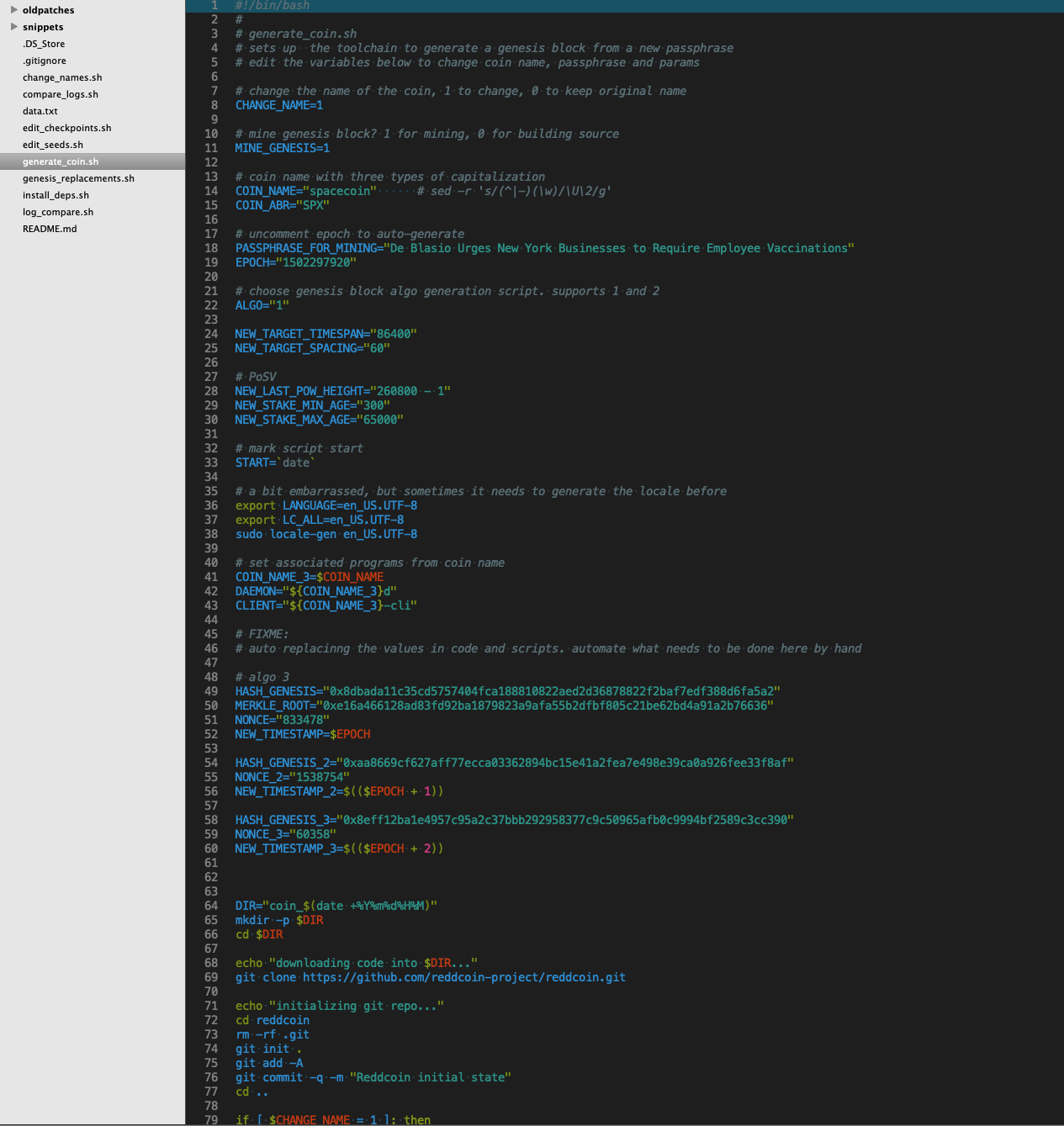
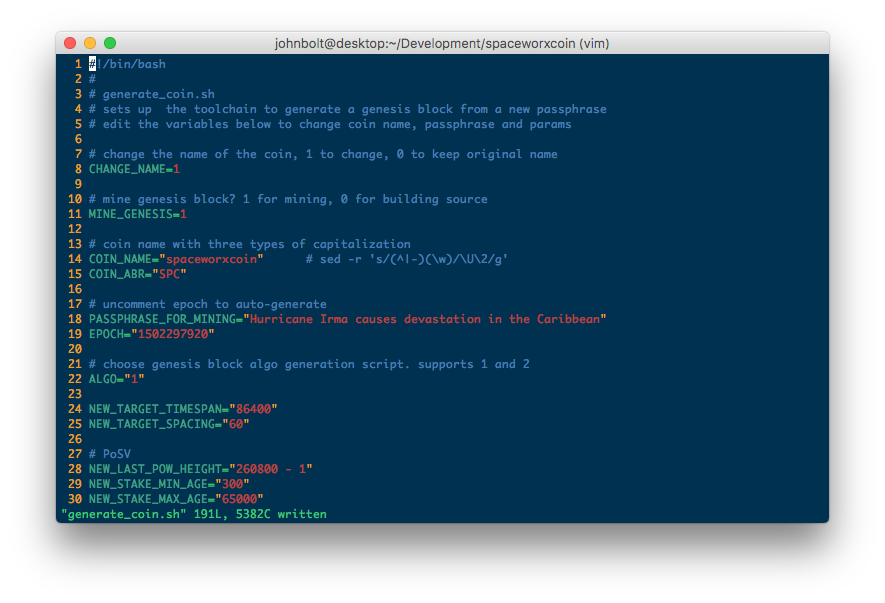
This is the process for creating a new blockchain, based on Reddcoin, a fork of LiteCoin that implements Proof of Stake Velocity as its method of
proof, alternativelly to Bitcoin's now questionable Proof of Work. The implementation is done in C++, make, and Bash Shell Script.
So what did we do here?
- We initiated a hard fork of an improvement over Bitcoin's network;
- We began mining a new chain of transactions;
- We tweaked technical parameters;
- We explored possible methods of scaling the network;
- We expolred the fork's operational codes (currently enabled, as well as disabled at the protocol level);
- Reprogrammed the original client to use with our new forked chain of transactions.
We set parameters for the coin such as target timespan and target spacing, we define parameters relevant to PoSV such as new stake minimum and maximum age, last PoW that should be considered, coin name, passphrase, icons, etc. We apply whatever patches and file replacements are deemed necesssary, and then we compile the full modified source.
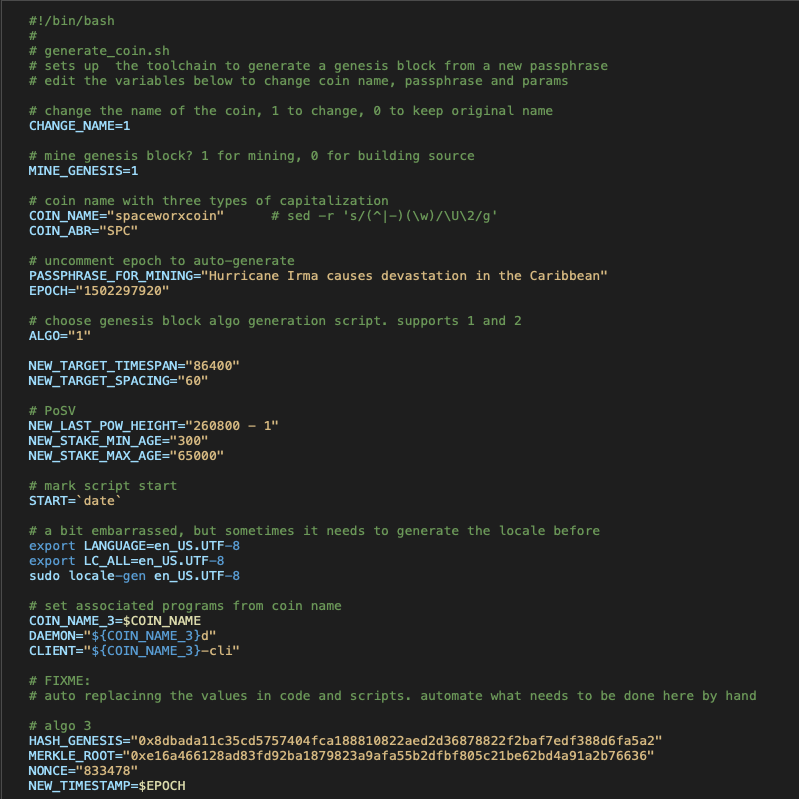
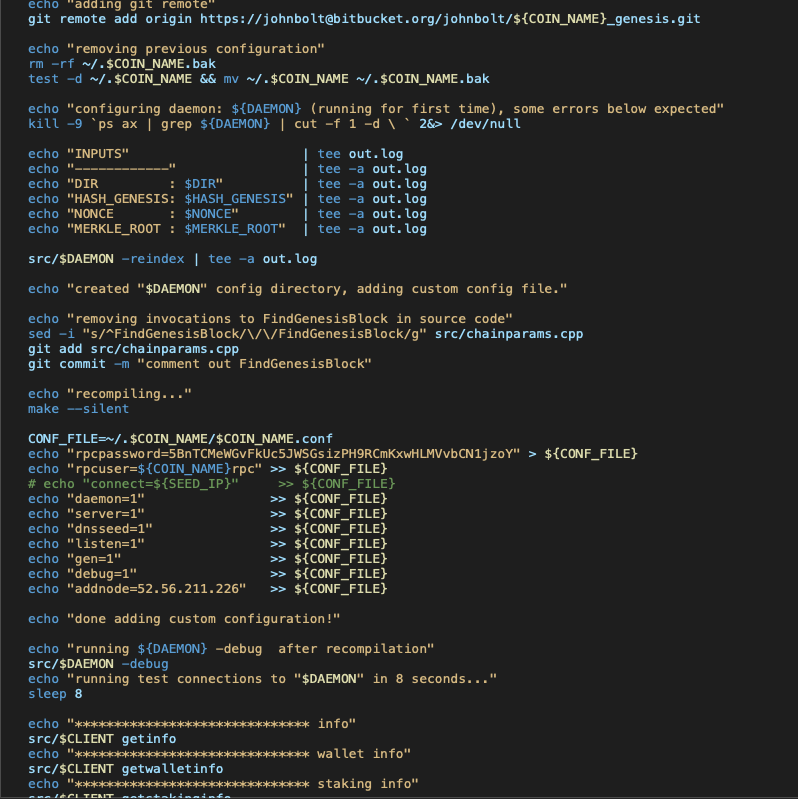
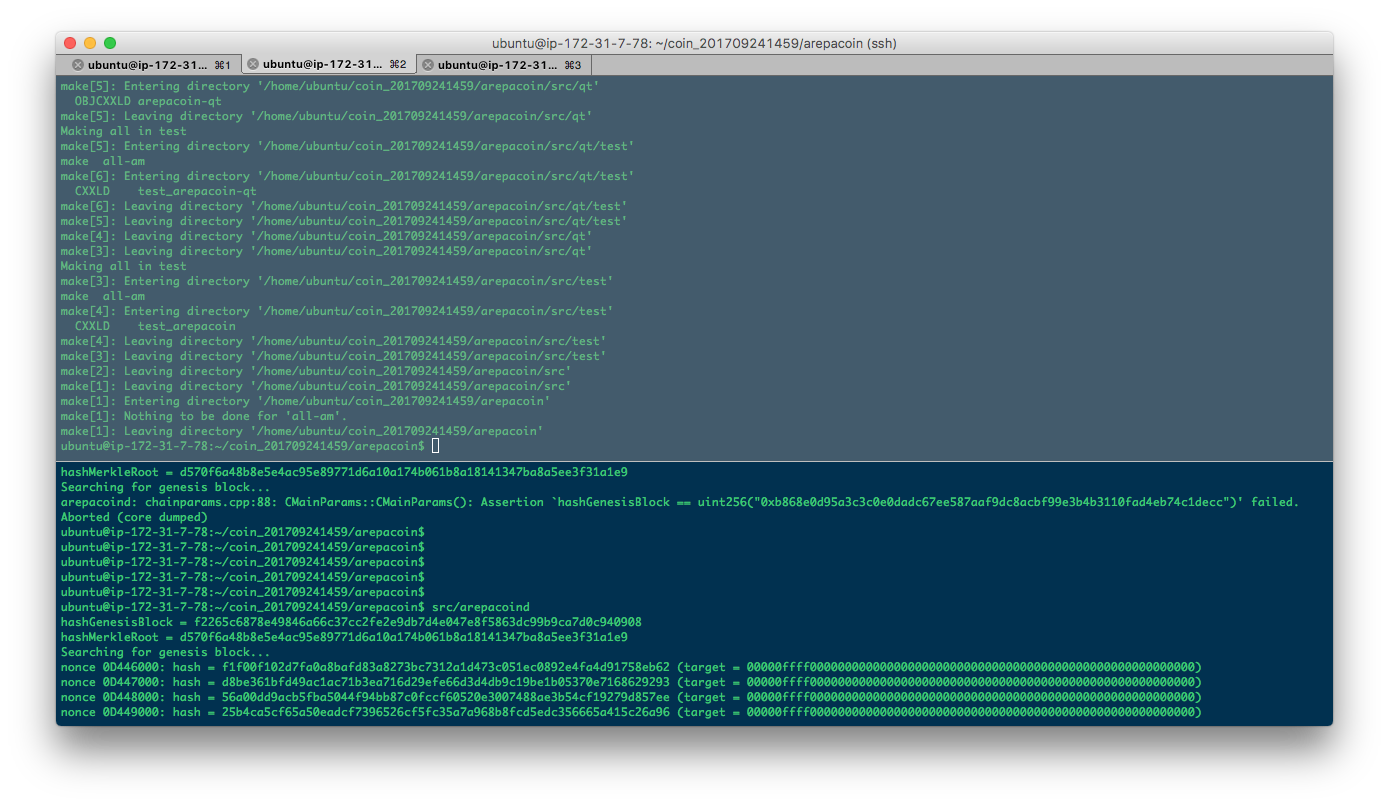
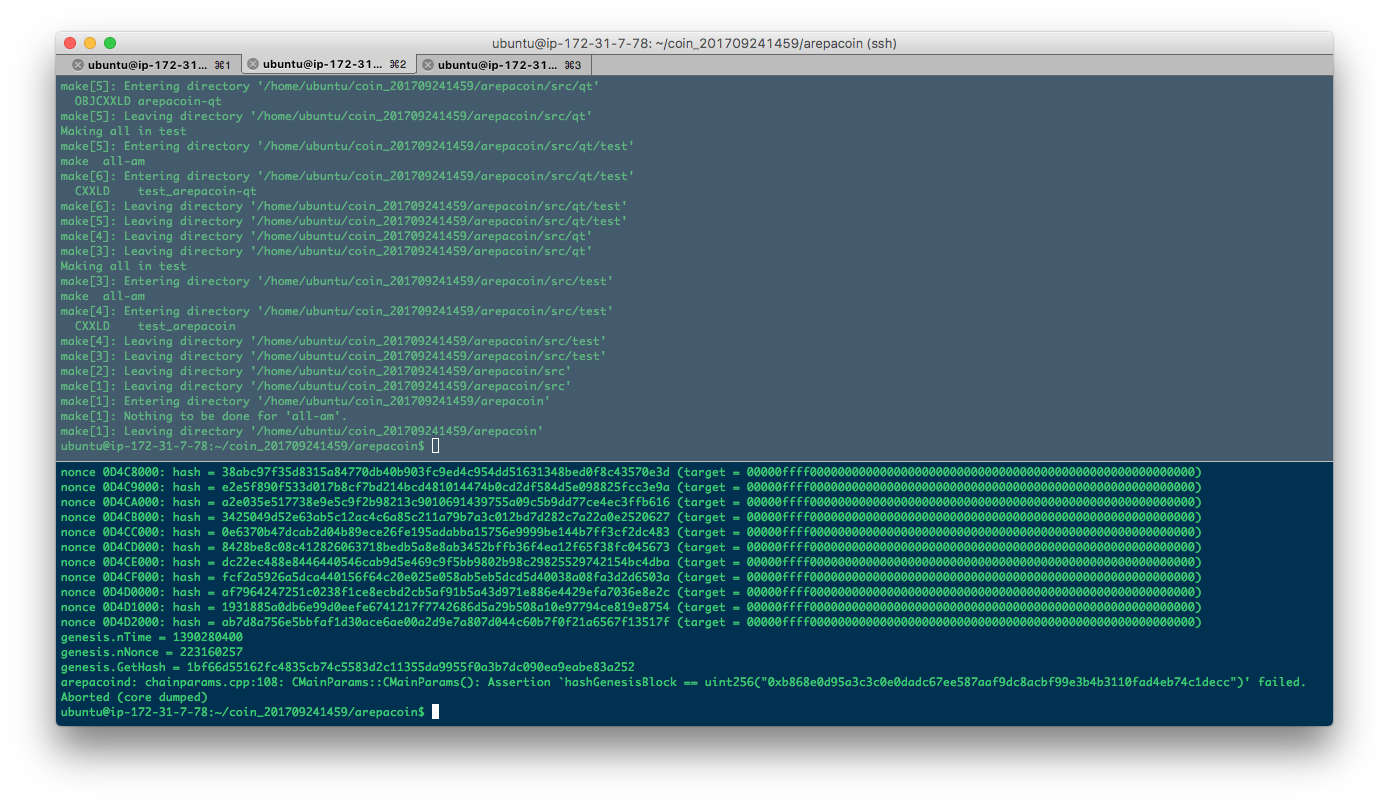
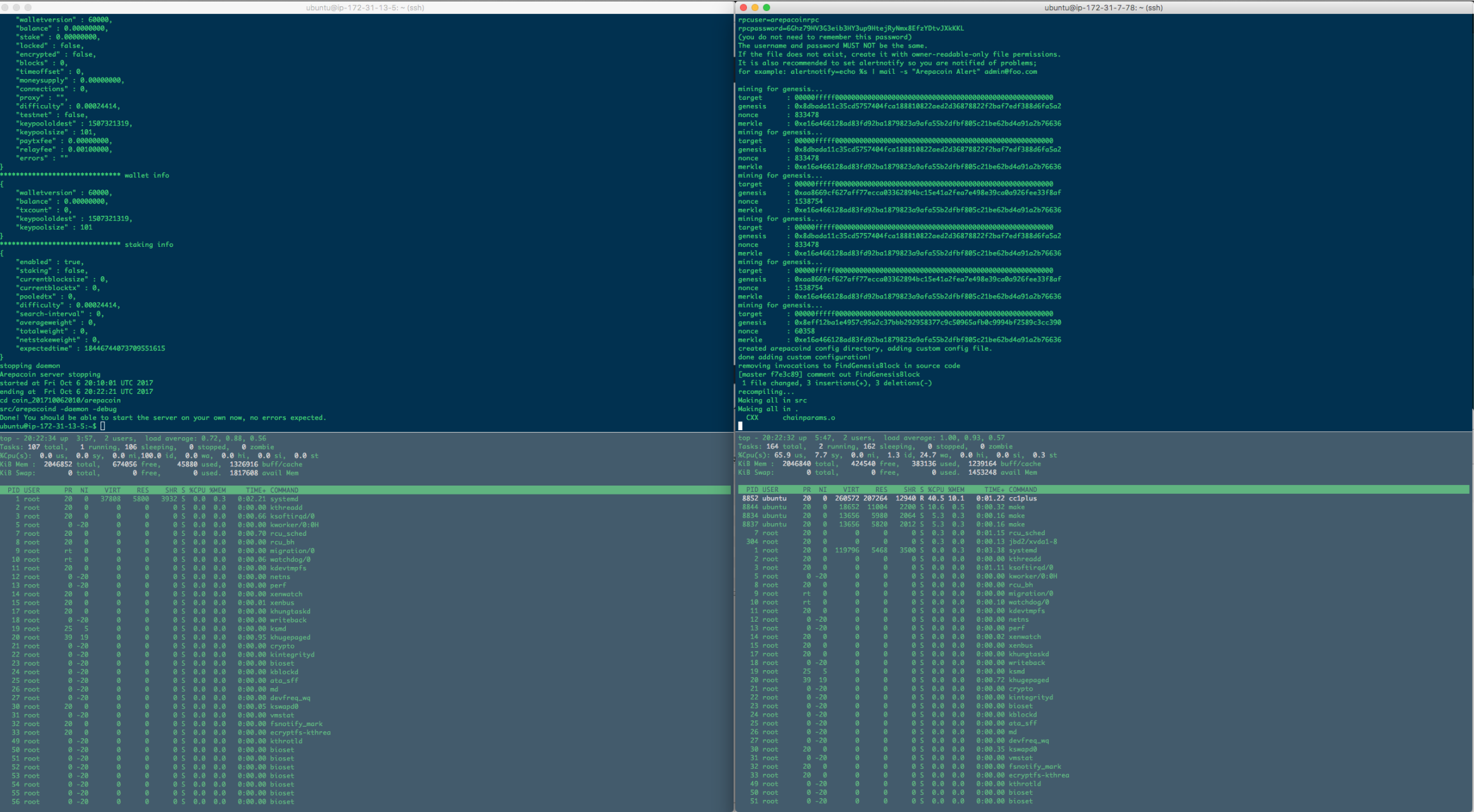
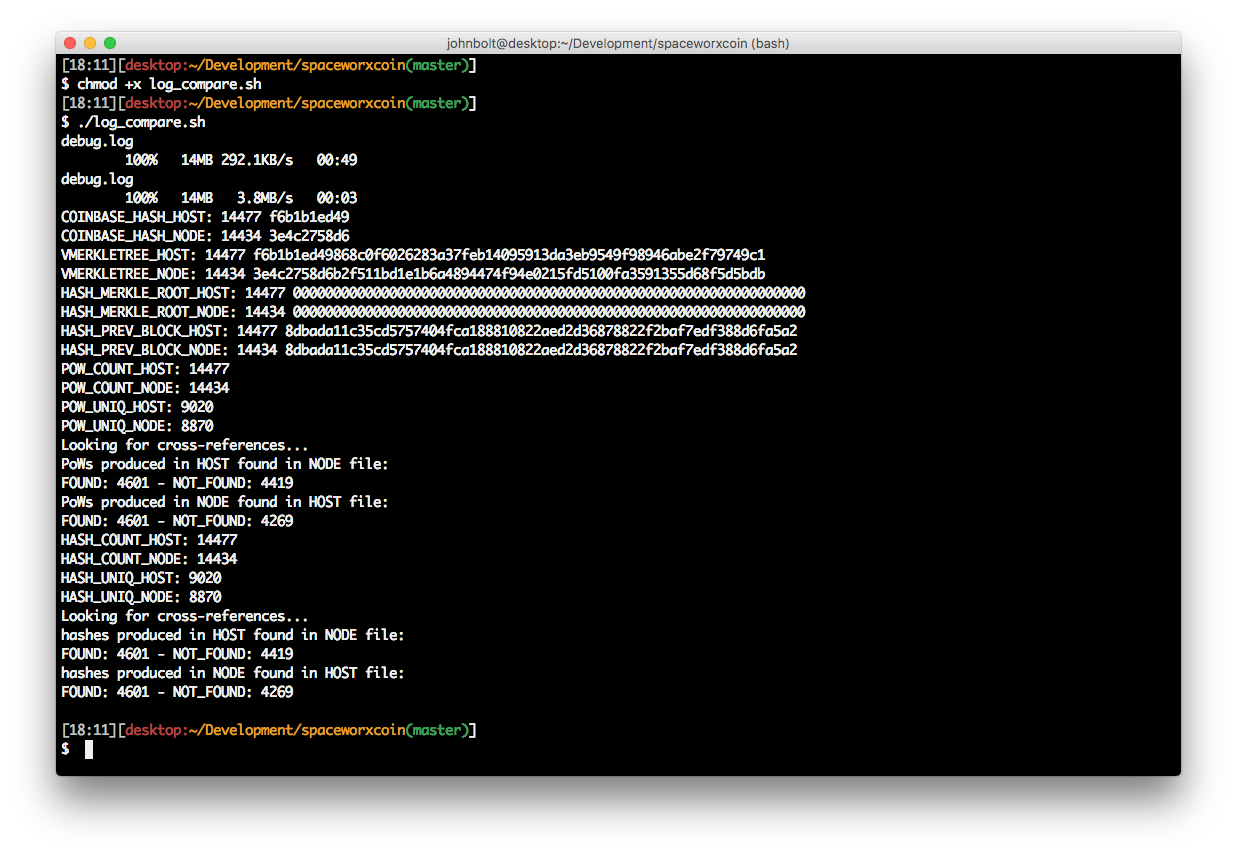
The compilation sometimes is local, but many times it's delegated to two EC2 instances - one for the source code of the HOST of the blockchain, and one for the source code of the NODE of the blockchain. They are also responsible for the load of having to do all calculations regarding the Genesis block, Merkle Root, and nonce.
Once they're all found, we have a new blockchain, ready to accept and record our distributed transactions. After all the post-processing, file
creation and configuration adjustments, we have access to full binaries of the blockchain, all object files, as well as the daemons and servers'
binaries, complete with a wallet in C++ qt, for the graphically inclined.
In our case, we worked with two Amazon AWS EC2 instances for compiling and deploying both client and server, which was a good compromise as the instances were powerful enough to handle the workload imposed by short but intense complilation bursts, and by virtue of the networking between them, also allowed for a constant correct-and-debug approach, flagging errors as soon as they appeared.
Full Article HereTrading Systems
Here are a few trading systems we've developed. More about it on the Trading page.
|
|
|
|
ATM |
Bazooka |
Drawdown Defender |
Betfair Prediction Markets - Trading API Automation - A Case Study
Betfair has been offering Prediction Markets since the year 2000. Their appeal, to me, is offering an API (Application Programming Interface) that allows the automation and adjustment of of betting patterns. There's also a lot of data, which caters to analysis and debugging. That, coupled with the financial incentives, makes the Betfair Prediction Markets very interesting to begin wth.
Betfair's innovation at the time was the creation of sports betting exchanges, a mix of a stock exchange and a sportsbook. Here people can buy or sell a bet, like they buy or short a stock. These live betting features are nowadays part of the standard offering of most sportsbooks, though some only offer live betting on one side of the book.
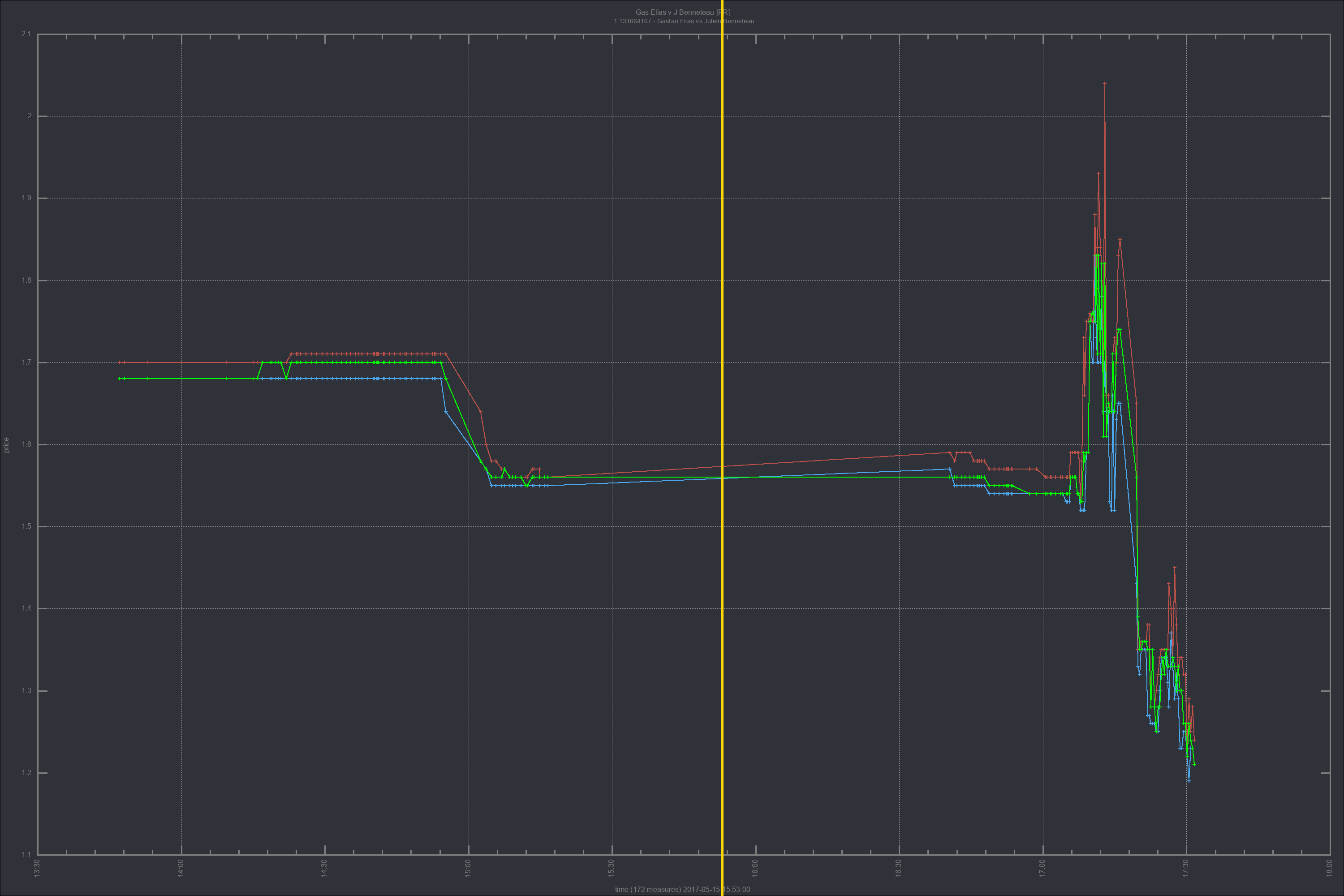
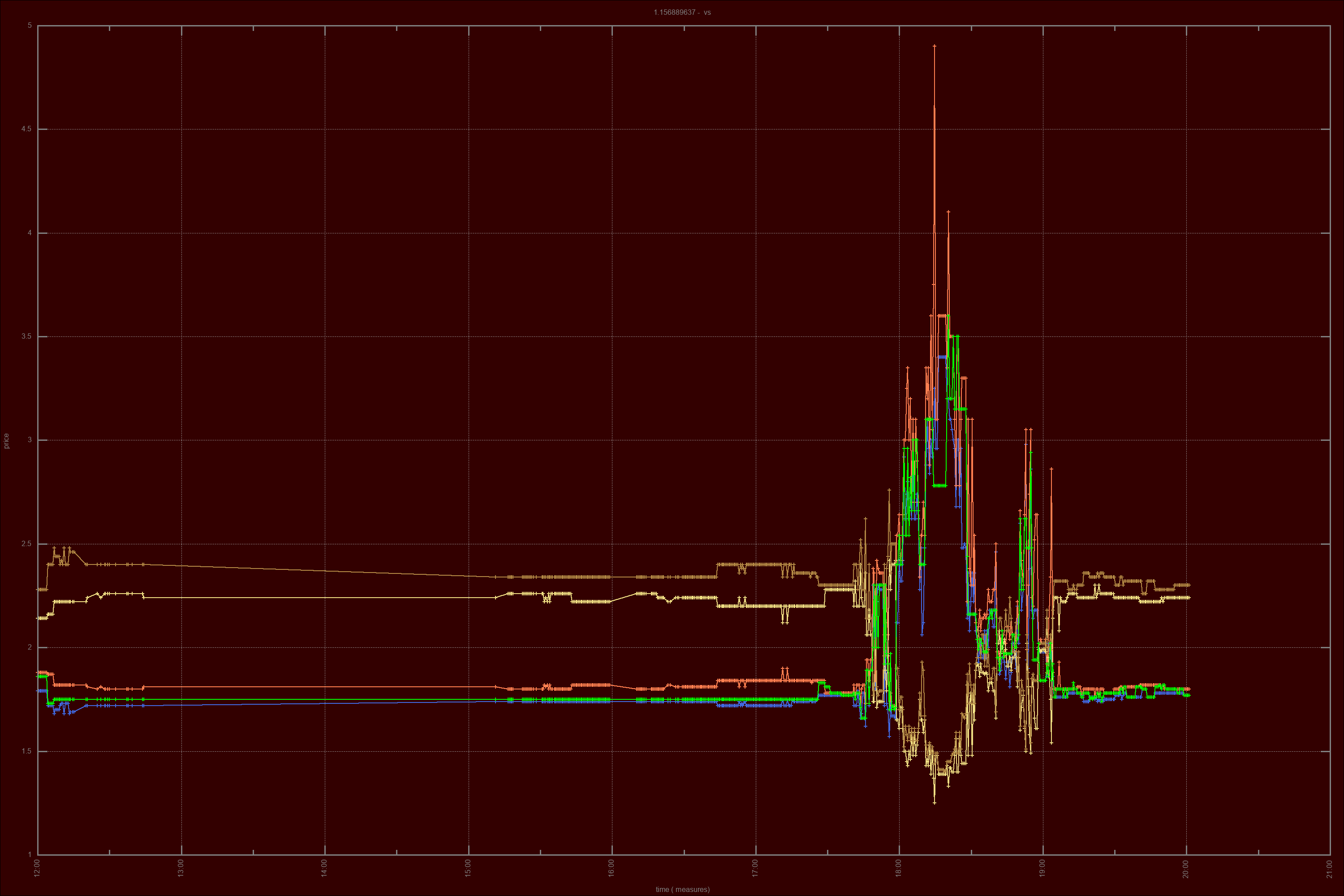
Our aim is clear - we explore inefficiencies. If you go straight to the charts, you can see the Buy price, the Sell price, and actual trade executed price.
How it works in traditional bets - say you have a team that is the underdog to begin with. If they score a goal right after the beginning, people who bet on the underdog will be very happy, because now there's a greater chance of winning. People that bet against them, on the other hand, will be stuck in a bet that now feels it was overpriced at the time of purchase. These are the market dynamics that betting exchanges capture, and where we can profit from.
In Prediction Markets, you can sell your position if you feel your outcome prediction is now different. You're not forced to stick with it until the end to see if it works out. Prediction Markets aggregate people who are willing to buy you out of your position, so you're not staked in the outcome anymore.
When you buy a stock you don't have to stick to it for eternity, you can just sell your position and exit at a profit or loss, and stop being invested in the outcome of the company. Here too, unlike a bet, positions aren't tied exclusivelly to the event's final outcome (the bet), and one can exit their positions earlier, if they find themselves in profit at any point holding the bet - before the event starts, in-play, or at the end.
There's dozens of associated Prediction Markets one can place wagers in: match winner, number of total goals, first to score, over/under, etc. One can try to find profitable opportunities, by manually threading throught the markets with your intuition and attemping to spot them. If you're going to go this route, you can also take notes using a typewriter, while you're at it. There's really better ways.
In the end, it doesn't really matter what you buy or sell, as long as you buy low and sell high. Soccer, Tennis, Horses, Doghounds, Prop Bets, there's really everything and all types of Prediction Markets.
This type of detailed market knowledge allow us to tweak our variables in order to position ourselves into profitability.
Betfair offers a programmable REST API, that allows users to retrieve market information, interpret it, and place bets accordingly - orders of magnitude faster than any manual, intuitive process. These systems may run unattended, while they scan Prediction Markets to select the ones that, at any point, fit our set of criteria, and then automatically place trades, as we define on our settings.
Instead of trying to force an opportunity, you define the criteria and let the oportunity find you.
This trading system is written in Ruby and uses Betfair's API-NG.
It provides trade management through a single configuration file, with the rules of the state machine, built with Docker and Kubernetes in mind, for mass concurrent deployment. This allows you to have configuration stored somewhere else, and just feed it to a container.
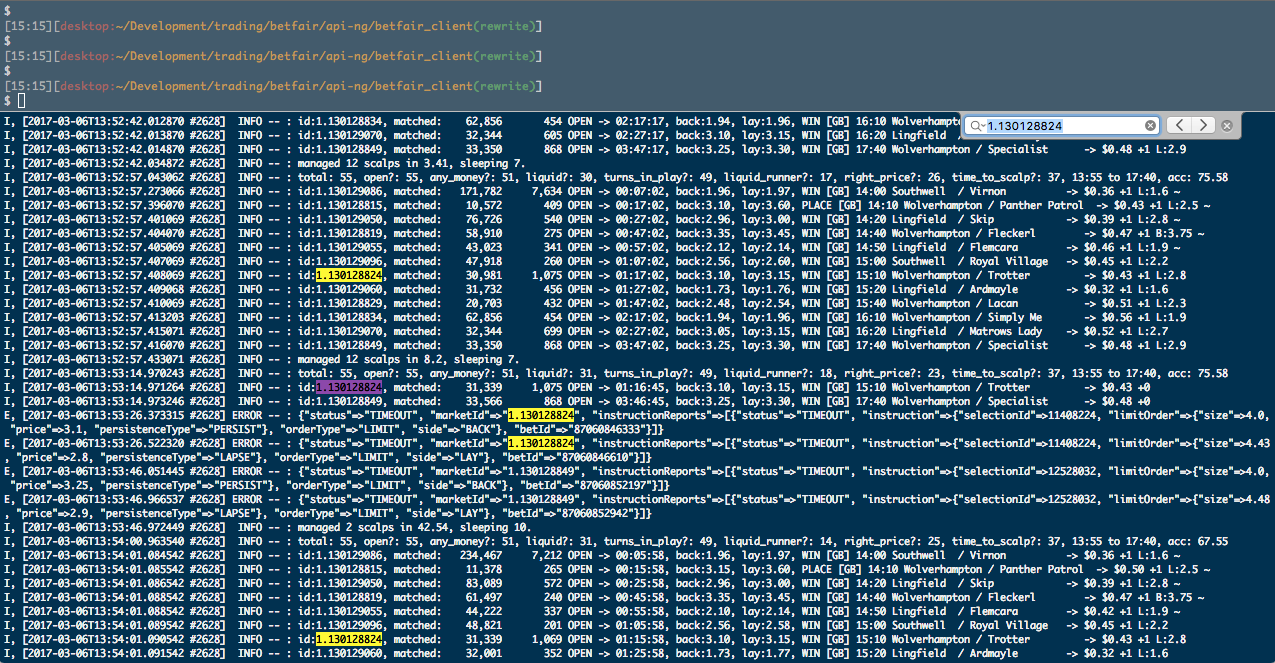
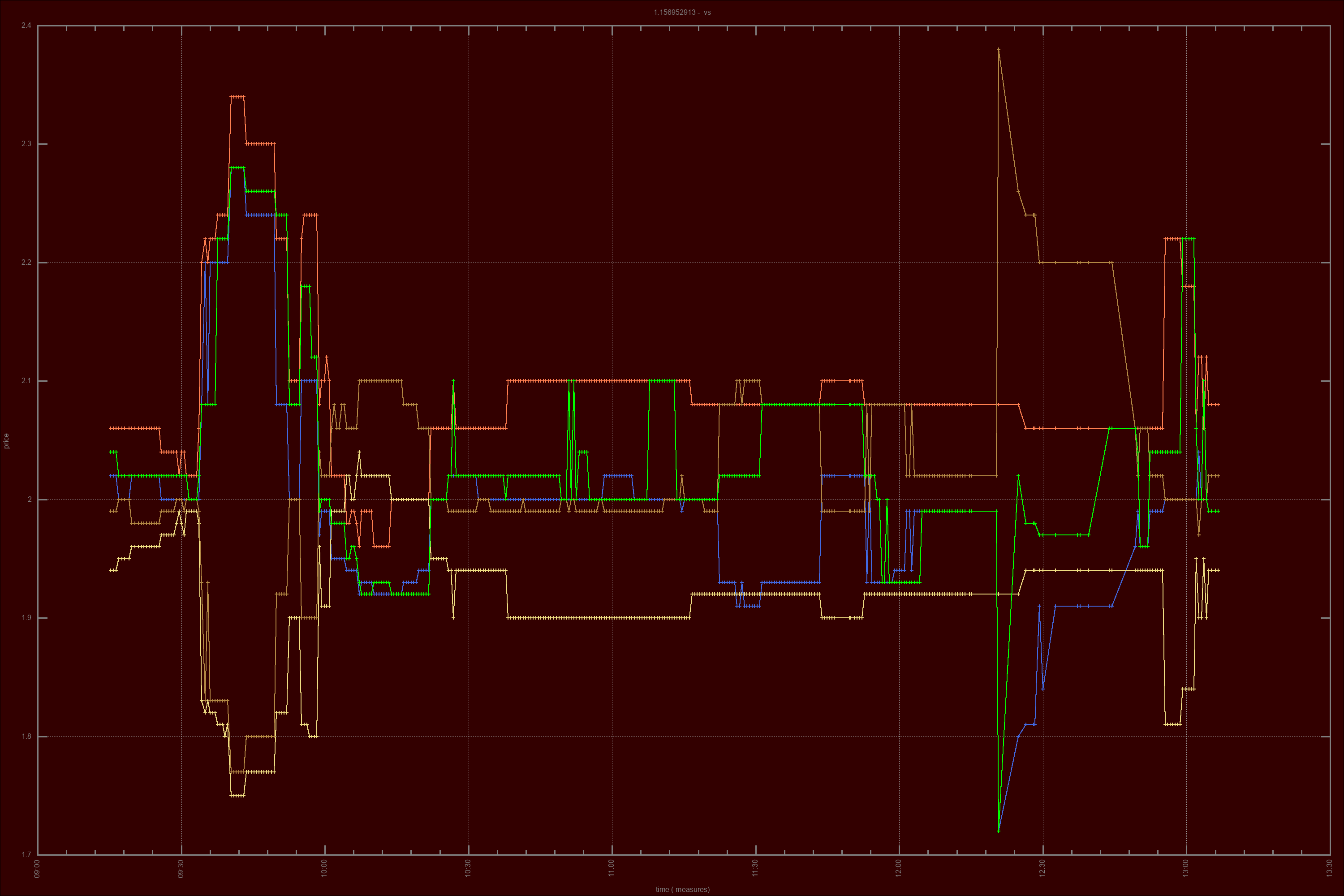
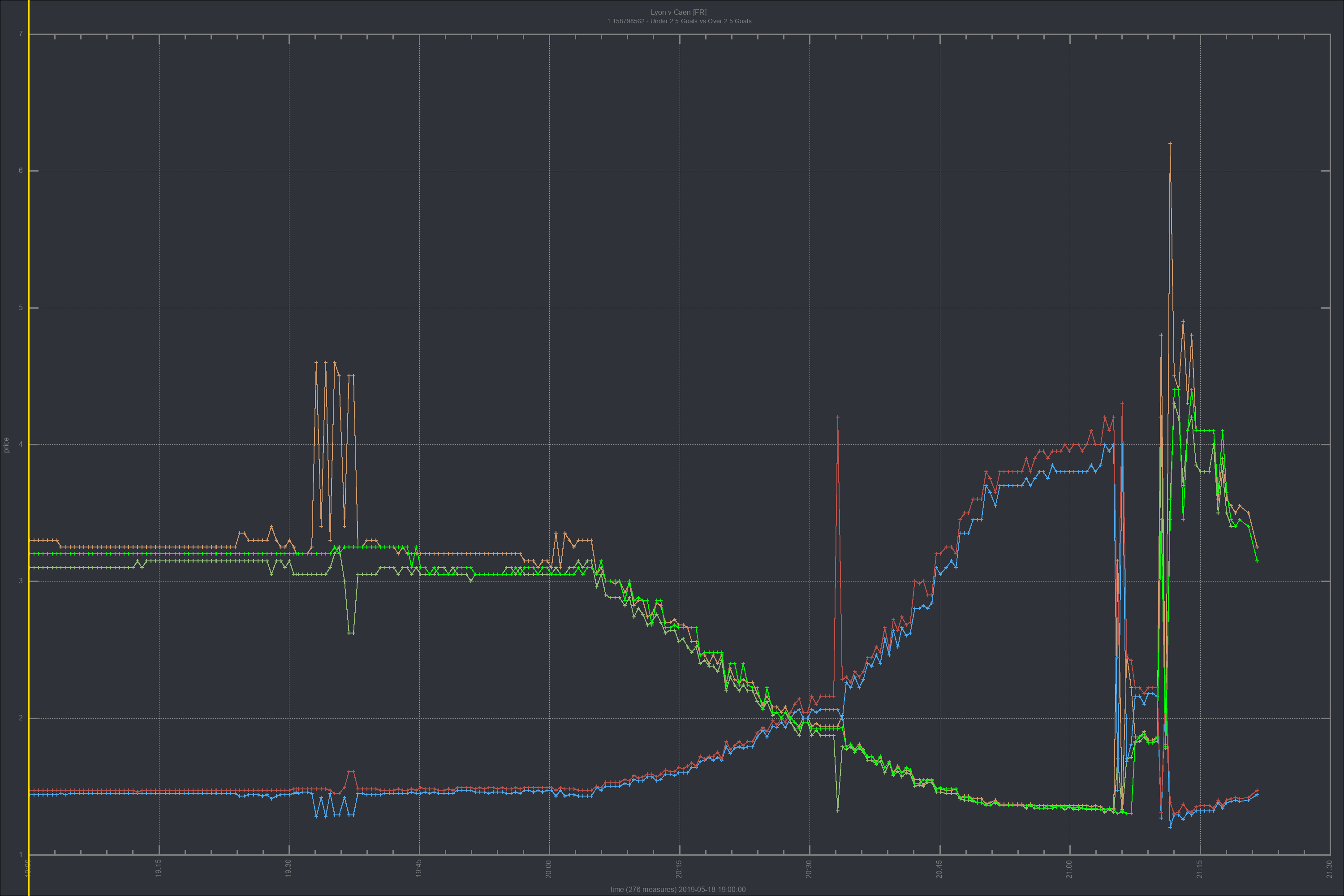

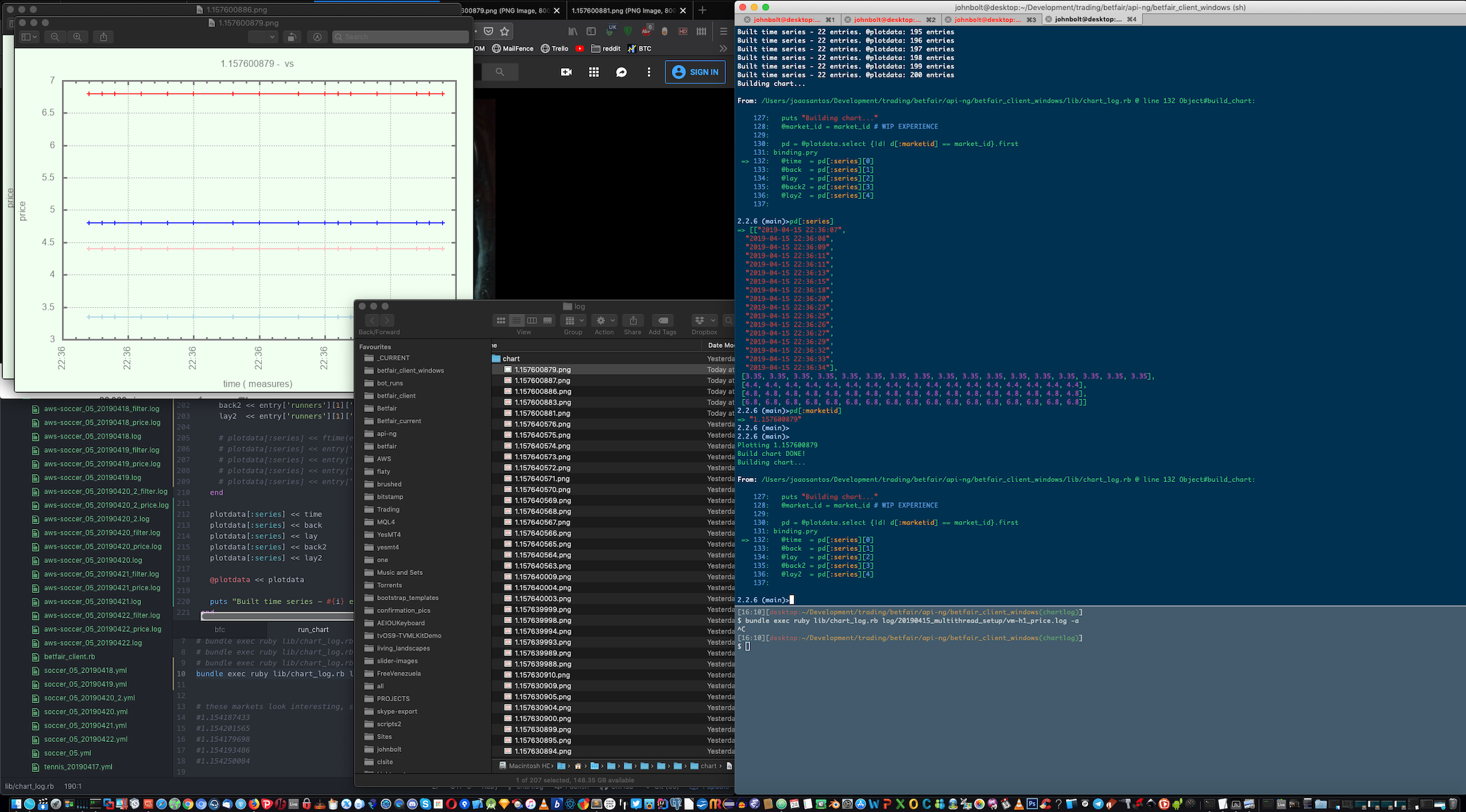
After authentication, the Prediction Market is scanned for candidates that conform to our conditions, a set of initial trades is placed, and then the state machine loops, all the time trying to find markets that fit our rule parameters. These include Minimum Liquidity, Time Window, Ods Price Interval, Number of Trades, and several other flexible parameters. When a market reaches full match of our conditions, it places new buy and sell positions, according to the specifications. If it doesn't reach a full match, or stops matching, it skips it.
The market is constantly being scanned to find changing trade conditions. As an example, we may define a minimum traded volume in the Prediction Market before placing any bets, we don't really want to drop money unless it's on a provenly participated market. The market, when we first look into the data, is momentarily matching all conditions, except for that specific one for minimum traded volume. If that market keeps trading between participants a little more, the trading volume will keep increasing, and as it exceeds our variable's threshold, it will at that point trigger our market volume rule, thus triggering all our evaluation filters to pass, at which point the state machine will proceed to then place trades.
We could leave it at that, but we're getting the data and keeping the logs, and we intent to use them. For future trades.
Why Betfair backtesting doesn't work - Let me know if there's any interest in this topic and if it's the case, I can consider writing a separate article to expand on this, there's a lot to tell.
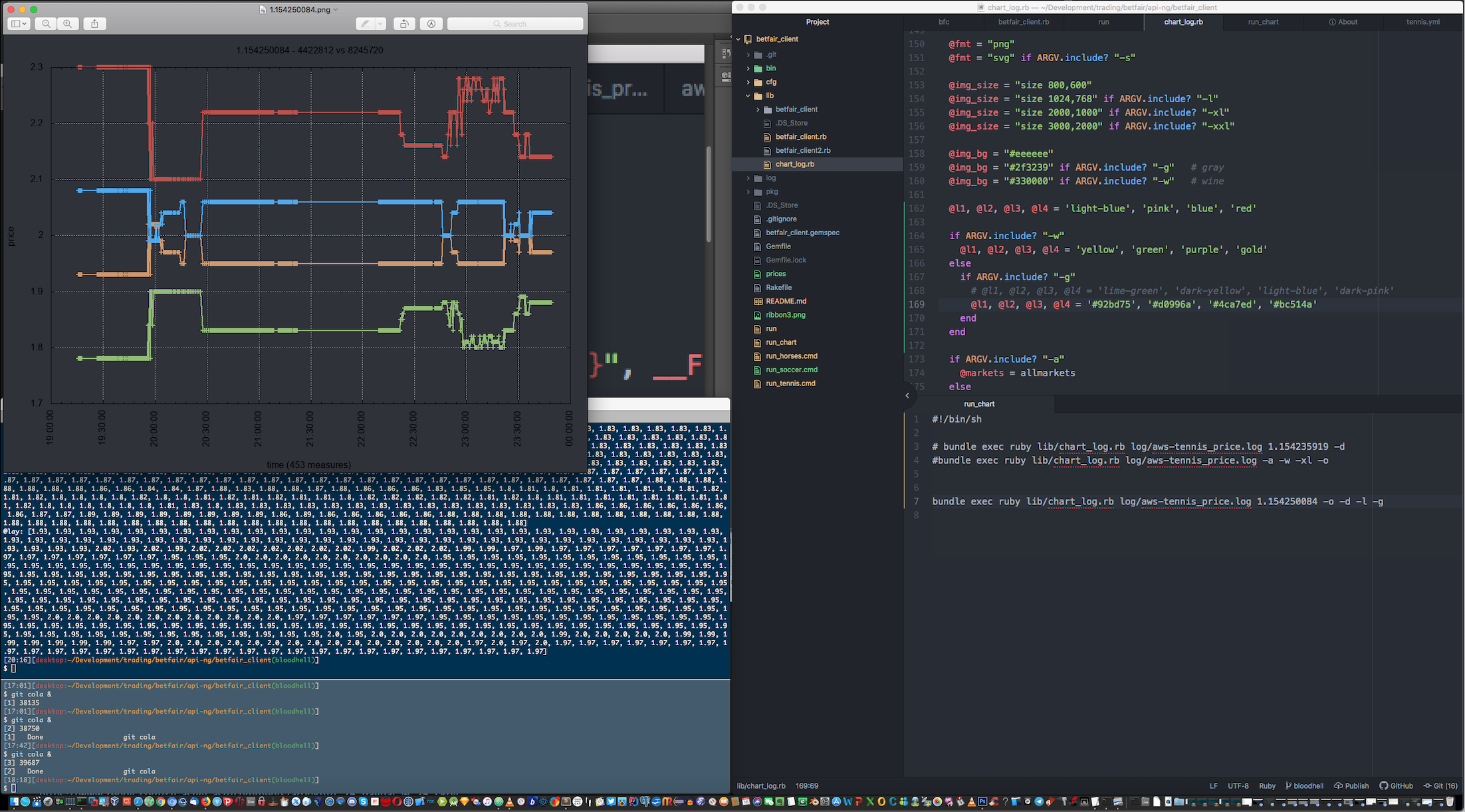
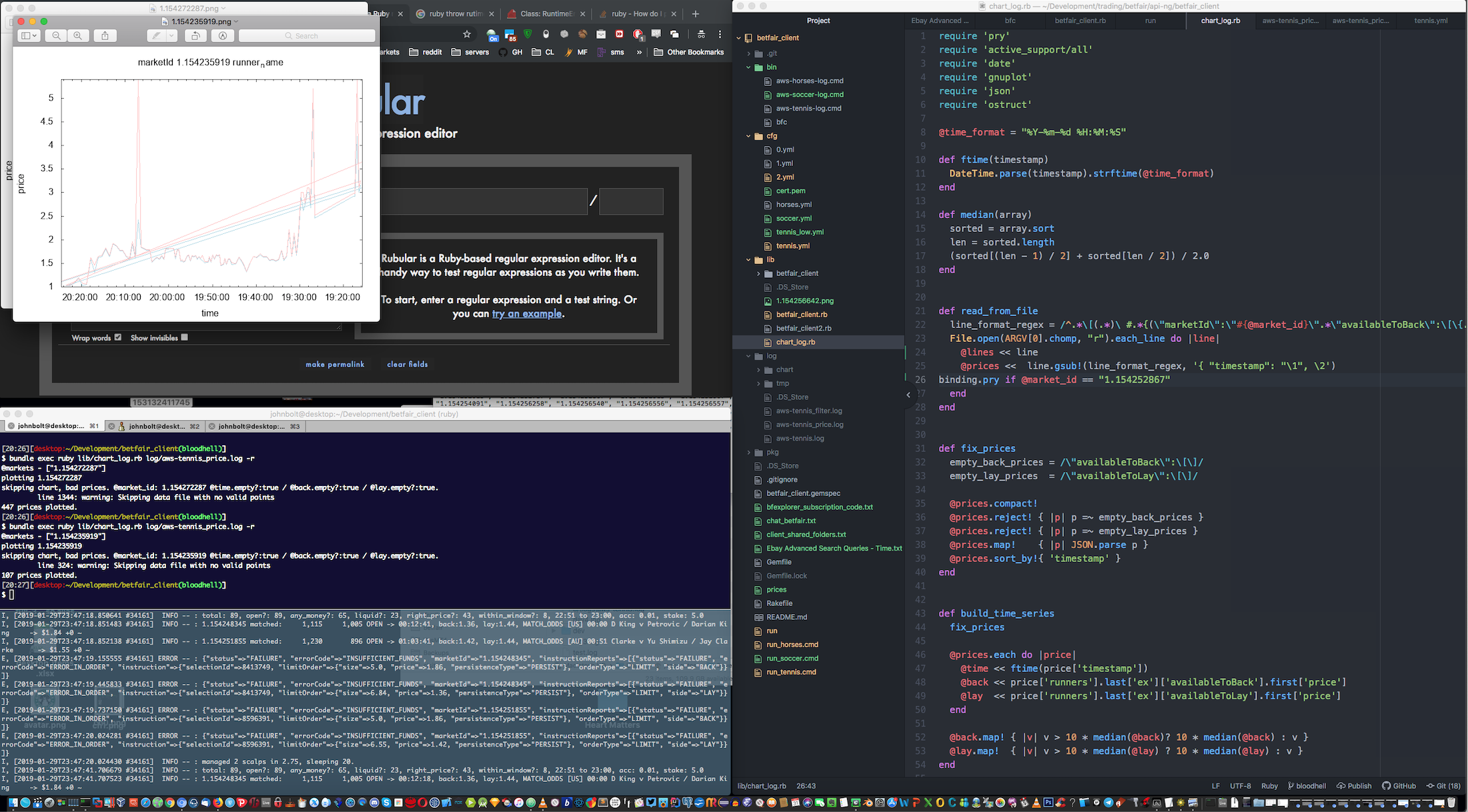
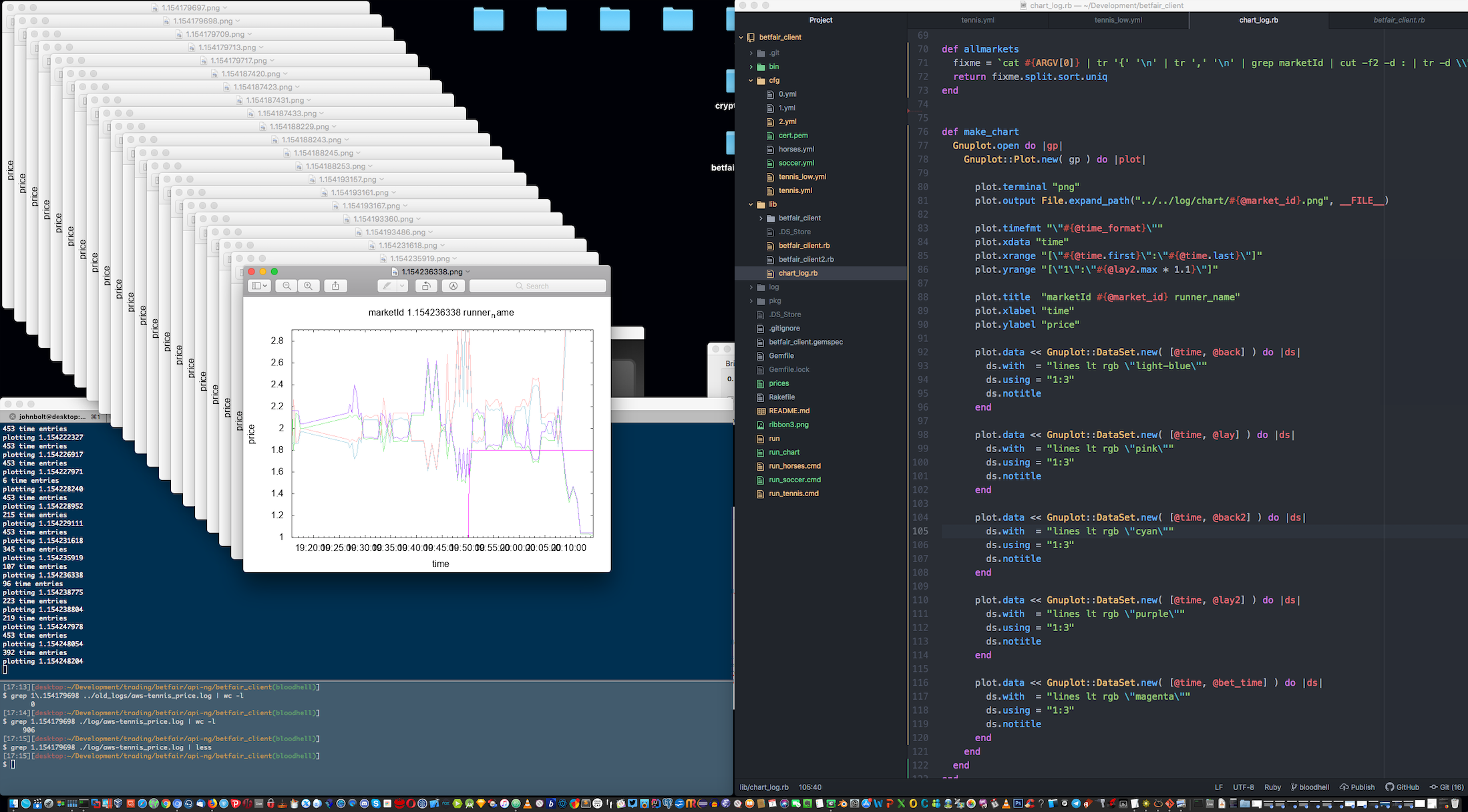
Vital and central use of the logging facility was made, to allow for price analytics and reporting. Past trades were long and heavily reviewd and, as a result, a parallel set of tools for trade analysis was created, including the ability to batch generate price analitics charts through log analisys, with Ruby and GNUPlot. This gives us further insight into the actual market workings and the obscure origins of price movements, besides Betfair's pricing information. Here, we go deep. We use Machine Learning processes based on Geometric Brownian Motion and Monte Carlo Simulations to improve on the price positions we took, and suggest future improvements based on the resulting analisys. These are produced as settings files for hopefully improved performance. Theoretically, markets are supposed to be random, but in practice, we see many price movements that counter the apparent randomness, based on volume. The tool also uses a variation of the Kelly Criterion to help with achieving optimal capital allocation by usign the signal as a weight that should be factored in at the time of sizing the position. The charting functionality allows us to generate hundreds of price charts with a single command. Instead of relying on the skin-deep information of Betfair's bid-ask prices, we have access to more. We plot actual orderbook information and effective traded prices, which show the hidden realities of price formation.
Deployment of the client may be made wherever a Ruby interpreter can be installed, supporting both Windows and Linux distributions. It's built with minimal external requirements. Ideally, it can be deployed to a Docker Swarm, or a Kubernetes cluster. It can be run locally from a desktop machine. In most of the screenshots you can see an Amazon EC2 deployment to a Windows VPS. It can also run as a backend to other systems with a front-end, which it has been. So really there's no limits to the API access this client provides.
Ruby was chosen first for its wide support. But also for being a language that allows a declarative style of programming, along with its functional abilities - in Ruby, everything is an object, so a functional style can be used locally on many occasions. This allows the functionality of each method to be very much self contained, relying mostly in the naming conventions to help us manage our state. In a sense, sort of like Prolog. But not really.
Other Trading Systems
Some more
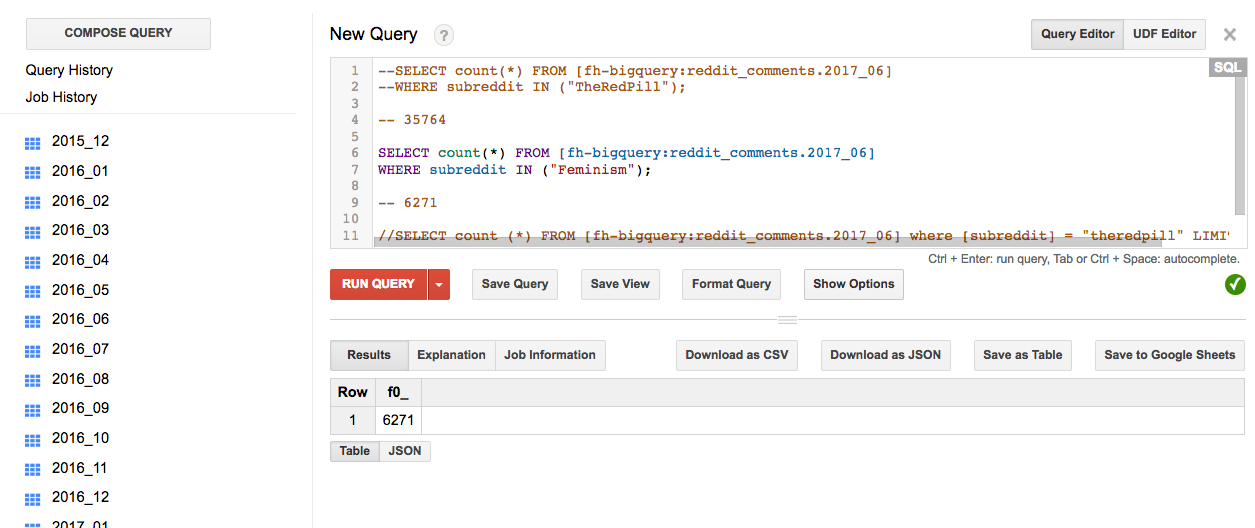
NLP with Google BigQuery and Reddit
Using Google's BigQuery to apply on-demand statistical analysis and NLP to public datasets containing Reddit's user information, including gender, comments, score and age.
Charity
TimeKeeper app for mobile TimeBanking, for charity purposes.